零一万物Yi-VL多模态语言模型上线 包括Yi-VL-34B、Yi-VL-6B两个版本
零一万物 Yi-VL 多模态语言模型是零一万物 Yi 系列模型家族的新成员,它在图文理解和对话生成方面具备卓越的能力。Yi-VL 模型在英文数据集 MMMU 和中文数据集 CMMMU 上都取得了领先成绩,展示了在复杂跨学科任务上的实力。
Yi-VL 模型分为 Yi-VL-34B 和 Yi-VL-6B 两个版本,它们在全新多模态基准测试 MMMU 中表现出色。MMMU 数据集包含了来自六大核心学科的11500个问题,涉及多种异构图像类型和交织的文本图像信息。Yi-VL-34B 在该测试集上以41.6% 的准确率超越了一系列多模态大模型,仅次于 GPT-4V,展现了强大的跨学科知识理解和应用能力。
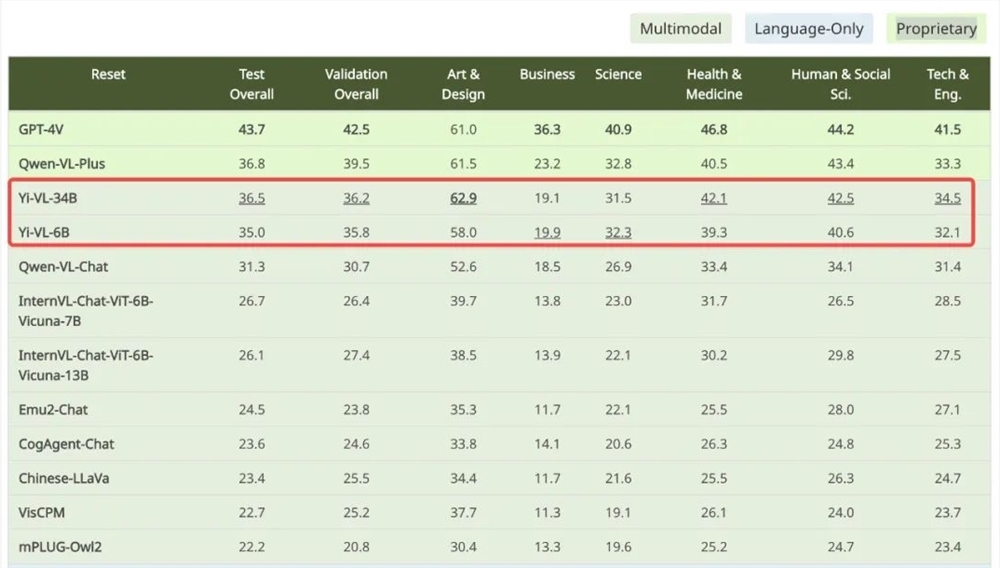
在针对中文场景打造的 CMMMU 数据集上,Yi-VL 模型也展现了独特优势。CMMMU 包含约12000道源自大学考试、测验和教科书的中文多模态问题。Yi-VL-34B 以36.5% 的准确率紧随 GPT-4V 之后,领先于当前最前沿的开源多模态模型。
Yi-VL 模型的核心亮点之一是基于 Yi 语言模型的强大文本理解能力,它只需对图片进行对齐,就可以得到优秀的多模态视觉语言模型。
Yi-VL 模型基于开源 LLaVA 架构,包含三个主要模块:Vision Transformer(ViT)、Projection 模块和大规模语言模型 Yi-34B-Chat 和 Yi-6B-Chat。ViT 用于图像编码,Projection 模块实现了图像特征与文本特征空间对齐的能力,大规模语言模型提供了强大的语言理解和生成能力。
Yi-VL 模型的训练过程分为三个阶段:第一阶段使用1亿张的 “图像 - 文本” 配对数据集训练 ViT 和 Projection 模块;第二阶段将 ViT 的图像分辨率提升至448x448,并使用约2500万 “图像 - 文本” 对进行训练;第三阶段对整个模型的参数进行训练,目标是提高模型在多模态聊天互动中的表现。
除了 Yi-VL 模型,零一万物技术团队还验证了使用其他多模态训练方法(如 BLIP、Flamingo、EVA)基于 Yi 语言模型可以快速训练出能够进行高效图像理解和流畅图文对话的多模态图文模型。
Yi-VL 模型地址:
https://huggingface.co/01-ai
https://www.modelscope.cn/organization/01ai
- 0000
- 0000
- 0000


 0002
0002- 0000