扎克伯格宣布Meta正在训练Llama 3 并将继续开源
要点:
Meta的联合创始人兼首席执行官扎克伯格宣布正在训练Llama3,并将继续以负责任的方式开源。
Llama是类ChatGPT开源模型的先驱,Meta在去年12月成立了AI联盟,致力于搭建开源大模型生态,同时开源了多个重要模型,包括文本生成音乐模型Audiocraft、多模态视频数据集Ego-Exo4D和视觉模型DINOv2。
Meta计划到2024年底拥有足够的AI算力资源,支持生成式AI和旗下AI部门FAIR的技术研究,预示着未来将有更多重磅产品开源,造福全球开发者和企业。
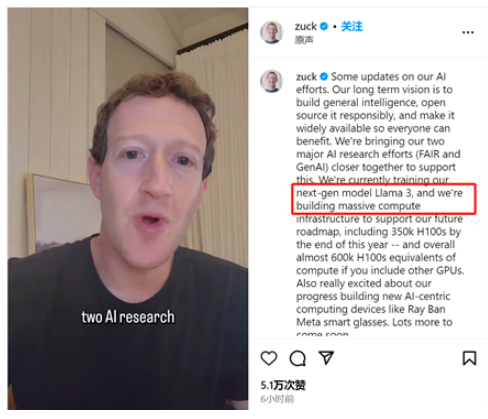
在最新的官方公告中,Meta的扎克伯格宣布了一项重要消息,即正在训练Llama3,并将继续以负责任的方式开源。这一消息对于企业和个人开发者来说都是一个好消息,因为他们可以继续以开源的方式使用与GPT-4、Gemini Ultra相媲美的大模型。扎克伯格表示,预计到2024年底,Meta将拥有庞大的AI算力资源,包括350,000块H100,进一步巩固其在生成式AI和FAIR技术研究方面的领先地位。
早在去年2月,ChatGPT火爆出圈,各国纷纷尝试开发类似的产品。Meta在同年12月成立了AI联盟,与甲骨文、英特尔、AMD、IBM、索尼等57家知名机构合作,旨在搭建开源大模型生态。这一联盟有多个目标,其中之一是促进从研究、评估、硬件、安全到公众参与的一整套流程。在2023年,Meta作为主要发起者和“盟主”,除了开源Llama系列,还发布了多个重要模型,包括文本生成音乐模型Audiocraft、多模态视频数据集Ego-Exo4D和视觉模型DINOv2。
Llama作为类ChatGPT开源模型的鼻祖,自去年2月起就备受关注。Meta于去年12月正式宣布开源Llama,并在此基础上进行了多次演进,其中LLaMA2是首个允许商业化的版本。该模型在数据训练方面采用公开可用的数据集,包括Common Crawl、C4、GitHub、维基百科等,总体标记数据量达到1.4万亿个Tokens左右。除了Llama系列,Meta还在开源方面取得了其他领域的成就,如音乐生成、多模态视频数据集和视觉模型等,为AI领域的开发者提供了丰富的工具和资源。
随着Meta继续扬帆起航,2024年将是开源的一年。Meta计划在未来公布更多的重磅产品,为全球开发者和企业带来更多福利。这一系列的举措表明Meta对生成式AI的庞大场景化落地充满信心,同时致力于推动整个开源大模型生态的发展。
- 0000
- 0000
 0001
0001- 0001
 0001
0001


