LeCun曝多模态LLM重大缺陷 提出Interleaved-MoF显著增强视觉理解能力
要点:
多模态大语言模型(MLLM)在视觉处理方面存在重大缺陷,特别是在处理视觉模式上的性能差距明显。
研究团队通过将DINOv2特征与CLIP特征结合的方法提升了多模态大模型的视觉功能,创造性地解决了视觉缺陷问题。
提出的「交错特征混合(Interleaved-MoF)」方法在MMVP基准中获得了10.7%的能力增强,显著提升了多模态大模型的视觉基础能力。
近期来自纽约大学和UC伯克利的研究团队在多模态大语言模型(MLLM)领域取得了重要突破,成功捕捉到了其在视觉理解方面存在的重大缺陷。研究人员发现,当前的MLLM在特定场景下,甚至在一些人类容易识别的图像问题上,表现不如随机猜测。这些问题包括对图像中朝向、状态、数量等基本要素的识别,显示了MLLM在视觉处理方面的局限性。

论文地址:https://arxiv.org/pdf/2401.06209.pdf
这项研究的关键发现是,MLLM的视觉缺陷主要源自「对比语言-图像预训练盲对(CLIP-blind pairs)」,即CLIP模型编码相似但在视觉上不同的图像,导致误导性的视觉嵌入。研究人员通过评估多个开源和闭源模型的性能发现,除少数模型外,大多数MLLM在视觉模式识别上都表现不佳,与人类视觉能力存在显著性能差距。
为解决这一问题,研究团队提出了「交错特征混合(Interleaved-MoF)」方法,将CLIP和DINOv2嵌入进行交错混合,成功提升了MLLM的视觉基础能力。实验证明,这种方法在MMVP基准中取得了10.7%的能力增强,而且不影响模型遵循指令的能力。通过此研究,对MLLM在视觉方面的性能提升打开了新的思路,为未来多模态AI技术的发展提供了有益的启示。
这项研究对于解决当前MLLM在视觉理解方面的缺陷问题具有重要意义。通过深入分析CLIP模型的视觉模式和MLLM性能之间的相关性,研究团队不仅提出了问题,还通过「交错特征混合」方法取得了实质性的改进。这不仅对AI领域的研究有着积极的推动作用,也为未来开发更强大、全面的多模态大模型奠定了基础。
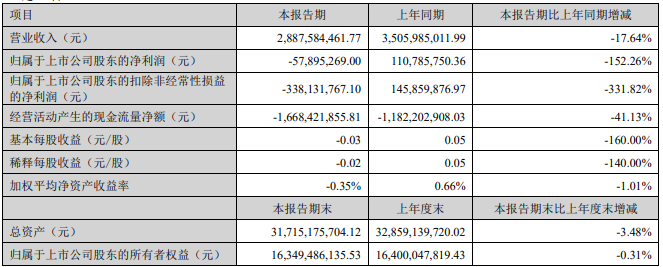
- 0002
- 0000
- 0000
- 0000
- 0000