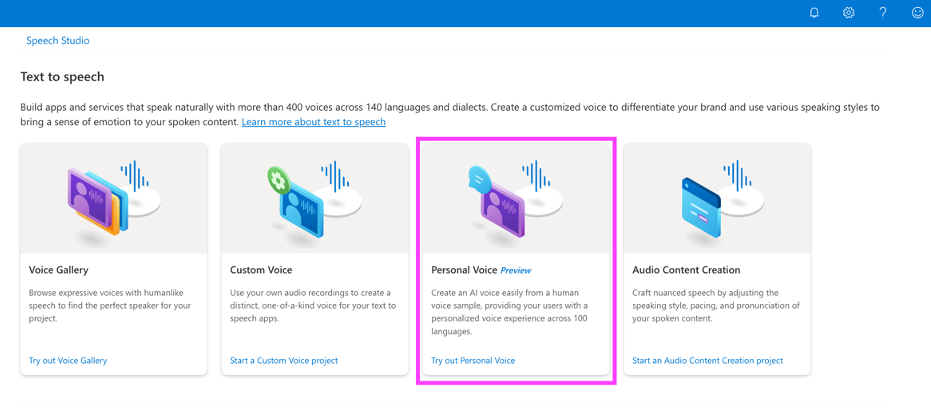
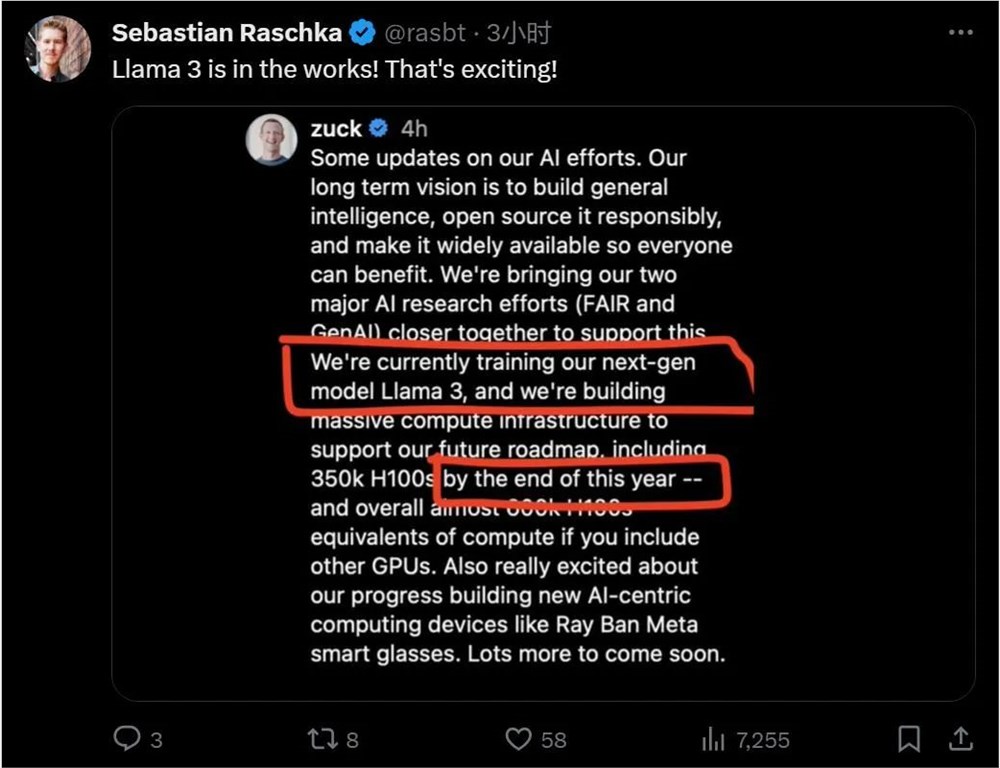
科学家创新技术用更少的GPU训练ChatGPT级别万亿参数模型
**划重点:**
1. 🌐 科学家使用世界最强大的超级计算机的仅8%算力,成功训练出ChatGPT规模的模型。
2. 🚀 Oak Ridge National Laboratory的研究团队在Frontier超级计算机上使用创新技术,仅用数千个AMD GPU训练了一个拥有万亿参数的语言模型。
3. 💡 通过分布式训练策略和各种并行技术,研究团队实现了在仅占用Frontier计算能力8%的情况下,训练1750亿参数和1万亿参数模型的百分之百弱扩展效率。
科学家们在世界上最强大的超级计算机上取得了巨大突破,仅使用其8%的计算能力,成功训练了一个与ChatGPT规模相当的模型。这项研究来自著名的Oak Ridge National Laboratory,他们在Frontier超级计算机上采用了创新技术,仅使用数千个AMD GPU就训练出了一个拥有万亿参数的语言模型。
通常,训练像OpenAI的ChatGPT这样规模的语言模型需要一个庞大的超级计算机。然而,Frontier团队采用了分布式训练策略,通过优化并行架构,仅使用Frontier计算能力的8%就成功完成了这一任务。具体而言,他们采用了随机数据并行和张量并行等技术,以降低节点之间的通信,同时处理内存限制。
这项研究的结果显示,在1750亿参数和1万亿参数模型的情况下,弱扩展效率达到了100%。此外,这个项目还取得了这两个模型的强扩展效率分别为89%和87%。
然而,训练拥有万亿参数的大型语言模型始终是一个具有挑战性的任务。研究人员指出,这个模型的体积至少为14TB,而Frontier中的一块MI250X GPU只有64GB。他们强调,需要进一步研究和开发方法来克服内存问题。
在面临大批次大小导致的损失发散问题时,研究人员提出,未来关于大规模系统训练时间的研究必须改善大批次训练,并采用更小的每副本批次大小。此外,研究人员呼吁在AMD GPU上进行更多工作,指出目前大多数大规模模型训练都是在支持Nvidia解决方案的平台上进行的。尽管研究人员为在非Nvidia平台上高效训练大型语言模型提供了“蓝图”,但他们认为有必要更深入地研究在AMD GPU上的高效训练性能。
Frontier在最近的Top500榜单中保持其作为最强大超级计算机的地位,超过了Intel推出的Aurora超级计算机。这项研究为未来训练巨大语言模型提供了宝贵的经验和方法,同时也突显了分布式训练和并行计算在实现这一目标上的关键作用。
- 0002
- 0000
 0000
0000- 0000
- 0000