字节与浙大联合推多模态大语言模型Vista-LLaMA 可解读视频内容
**划重点:**
- 💡 Vista-LLaMA是一种专为视频内容理解而设计的多模态大语言模型,能够输出高质量视频描述。
- 🔬 通过创新的视觉与语言token处理方式,Vista-LLaMA解决了在视频内容中出现“幻觉”现象的问题。
- 🚀 改良的注意力机制和序列化视觉投影器提高了模型对视频内容的深度理解和时序逻辑把握。
在自然语言处理领域,大型语言模型如GPT、GLM和LLaMA等的成功应用已经取得了显著的进展。然而,将这些技术扩展到视频内容理解领域则是一项全新的挑战。字节跳动与浙江大学合作推出的Vista-LLaMA多模态大语言模型旨在解决这一问题,实现对视频的深度理解和准确描述。
技术创新路径:
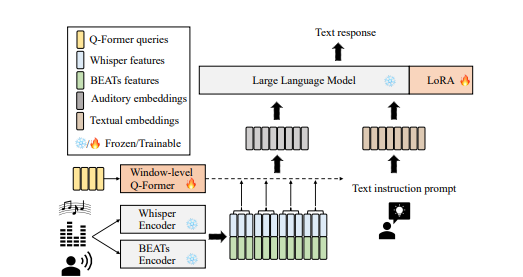
在处理视频内容时,传统模型存在一个问题,随着生成文本长度的增加,视频内容的影响逐渐减弱,产生了“幻觉”现象。为解决这一问题,Vista-LLaMA通过独特的视觉与语言token处理方式,维持视觉和语言token之间的均等距离,避免了文本生成中的偏差。该模型还采用改良的注意力机制和序列化视觉投影器,提高了模型对视频内容的深度理解和时序逻辑把握。
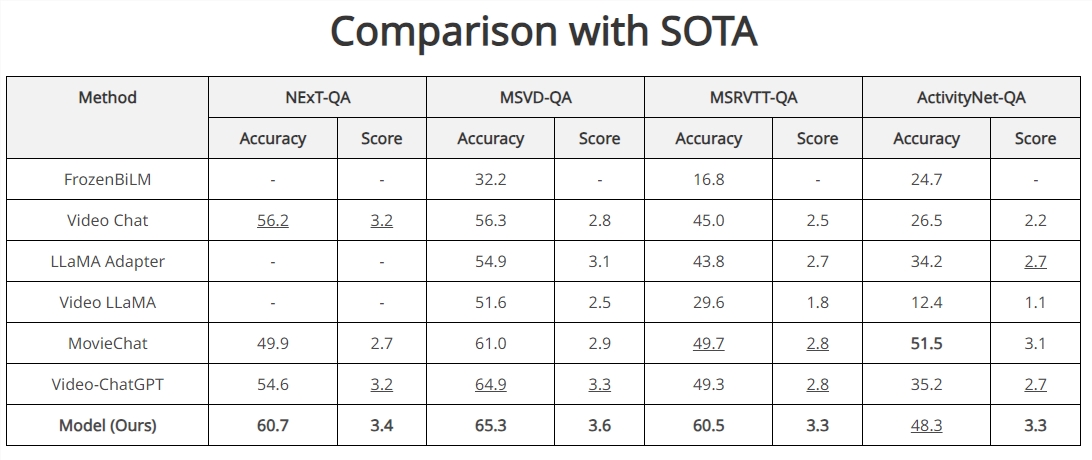
基准测试结果:
Vista-LLaMA在多个开放式视频问答基准测试中表现卓越,尤其在NExT-QA和MSRVTT-QA测试中取得了突破性成绩。其在零样本NExT-QA测试中实现了60.7%的准确率,在MSRVTT-QA测试中达到了60.5%的准确率,超过了目前所有的SOTA方法。这些结果证明了Vista-LLaMA在视频内容理解和描述生成方面的高效性和精准性。
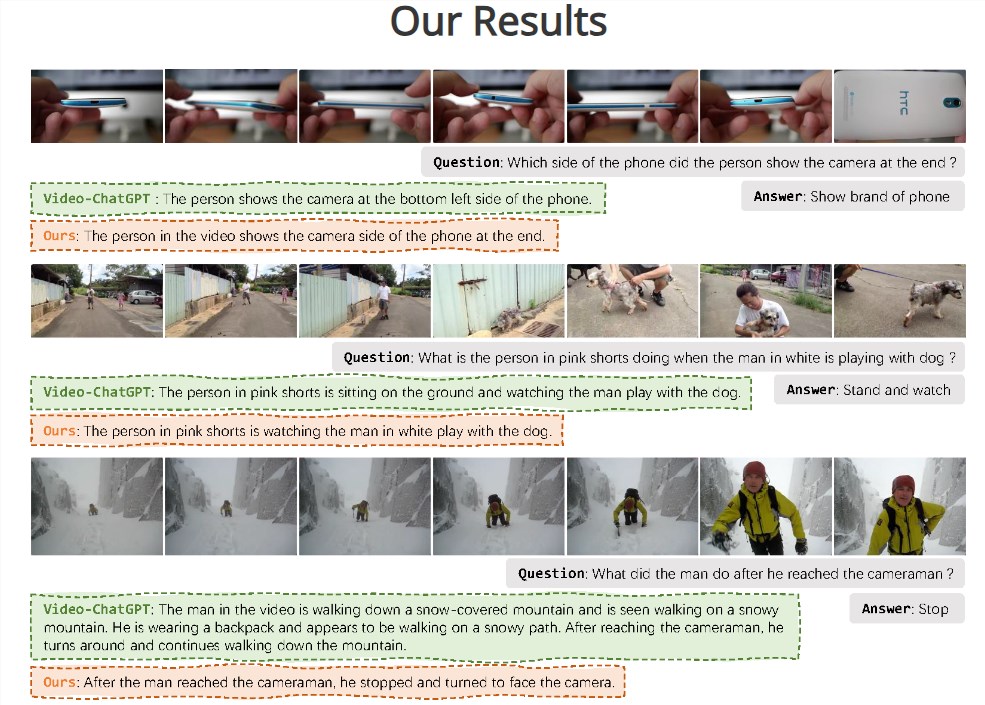
CineClipQA新数据集:
Vista-LLaMA的提出伴随着CineClipQA新数据集的发布,该数据集包含了来自五部电影的153个视频片段,每个片段附有16个定制问题,共计2448个问题。这一数据集为多模态语言模型的发展提供了更丰富的训练和测试资源。
Vista-LLaMA的出现为视频内容理解和生成领域带来了新的解决框架,推动了人工智能在视频处理和内容创作方面的发展。其在长视频内容方面的显著优势为未来多模态交互和自动化内容生成领域提供了广泛的机遇。
- 0001
- 0000
- 0000
- 0000
- 0000