AI透视眼!Wild2Avatar可逼真渲染视频中被遮挡的人物
**划重点:**
1. 🚀 **挑战与解决方案**:面对现有研究在理想条件下渲染3D人物的局限性,Wild2Avatar专注于解决真实场景中摄像头视野被遮挡导致部分遮挡的问题。
2. 🔍 **创新方法**:通过场景参数化,将场景分解为遮挡、人物和背景三个部分,并利用神经辐射场分别建模人物和遮挡/背景,以实现对被遮挡人物的准确渲染。
3. 🌟 **实验验证**:通过在野外视频上的实验证明,Wild2Avatar方法在解决真实世界场景下的挑战方面取得显著成效。
在渲染移动人物的视觉外观时,面对摄像头视野被遮挡的问题是一项巨大的挑战。大多数现有研究在理想条件下渲染3D人物,要求场景清晰且无障碍。然而,在真实世界场景中,可能会有障碍物阻挡摄像头视野,导致人物出现部分遮挡,这使得这些传统方法无法应用。
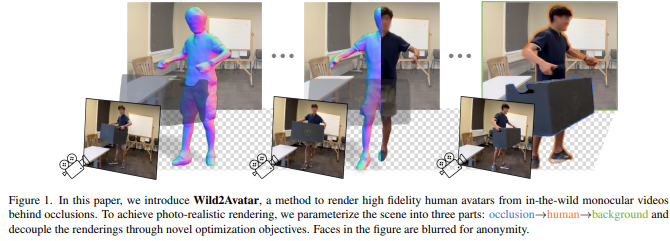
为了解决这一问题,著名人工智能教授李飞飞团队推出了Wild2Avatar,这是一种专为视频中被遮挡人物设计的神经渲染方法。
研究团队提出了一种考虑遮挡的场景参数化方法,将整个场景分解为遮挡、人物和背景三个部分。此外,我们设计了广泛的客观函数,以帮助强化人物与遮挡、背景的分离,并确保对人物模型的完整性。我们通过在野外视频上进行实验证明了我们方法的有效性。
方法介绍:
为了实现逼真的呈现,该方法将场景参数化为三个部分:遮挡物 → 人 → 背景,并通过新颖的优化目标将这些渲染解耦。为了处理在真实世界场景中可能出现的遮挡情况,该方法引入了感知遮挡的场景参数化,将场景解耦为遮挡、人和背景三个部分。此外,该方法设计了广泛的客观函数,以帮助强化将人从遮挡和背景中解耦,并确保人体模型的完整性。
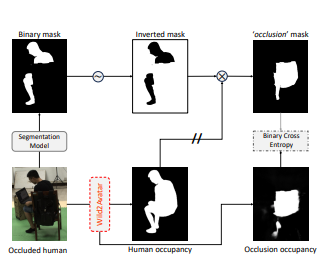
具体来说,方法使用了场景的自分解技术,通过倒置球面参数化的扩展,引入了感知遮挡的场景参数化。在这个参数化中,除了第一个由倒置球面参数化定义的球体外,引入了第二个内部球体,并将从摄像机到内部球体边缘的区域定义为遮挡区域。通过分开渲染这个区域,可以将遮挡与场景的其余部分解耦。为了确保对人的高保真和完整呈现,方法通过像素级光度损失、场景分解损失、遮挡解耦损失和几何完整性损失的组合来聚合三个渲染。

该方法的贡献包括:
引入了感知遮挡的场景参数化,将场景解耦为遮挡、人体和背景三个部分。提出了一种新的渲染框架,分别渲染这三个部分,并设计了新颖的优化目标,以确保遮挡的清晰解耦和更完整的人体呈现。在具有挑战性的遮挡密集野外视频上对方法进行了评估,展示了其在呈现遮挡人体方面的有效性。
Wild2Avatar通过与Vid2Avatar(基线)和原始视频的对比,呈现了其在解决被遮挡人物渲染挑战方面的独特性能。
项目体验网址:https://top.aibase.com/tool/wild2avatar
论文网址:https://arxiv.org/pdf/2401.00431.pdf
- 0000

 0001
0001- 0000
- 0000

 0001
0001