维基百科+大模型打败幻觉!斯坦福WikiChat性能领先GPT-4
要点:
1. 维基百科 大模型打败幻觉,斯坦福WikiChat在事实准确性和其他指标上表现优秀。
2. 斯坦福研究人员利用维基百科数据训练大模型WikiChat,成功减轻了幻觉问题,并在事实准确性和对话性方面超过了其他模型。
3. 通过优化和改进,WikiChat在各个方面的性能都显著领先,尤其在事实准确性方面达到了97.3%。
斯坦福大学的研究人员利用维基百科数据训练了一个大模型,命名为WikiChat,通过优化和改进,成功解决了大模型的幻觉问题,并在事实准确性和其他指标上表现优秀。他们的最佳模型在新的基准测试中获得了97.3%的事实准确性,远远超过了GPT-4的66.1%。此外,WikiChat还在相关性、信息性、自然性、非重复性和时间正确性方面领先其他模型。
论文地址:https://aclanthology.org/2023.findings-emnlp.157.pdf
项目代码:https://top.aibase.com/tool/wikichat
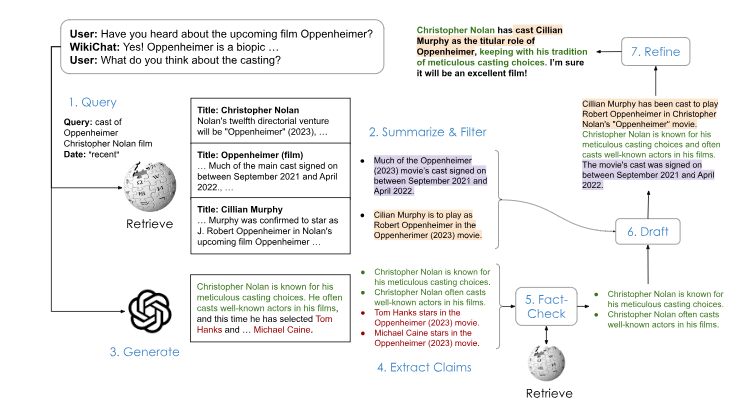
为了解决幻觉问题,研究人员采用了检索增强生成(RAG)的方法,并添加了几个重要步骤来进一步减轻幻觉,并改进对话性指标。通过这些优化,WikiChat在事实准确性方面比微调后的SOTA RAG模型Atlas高出8.5%。此外,研究人员还将基于GPT-4的WikiChat提炼成7B参数的LLaMA模型,这个模型在事实准确性方面能达到91.1%的高分,并且运行速度提高了6.5倍,能效更好,可以本地部署。
然而,解决大模型的幻觉问题并不容易。一般情况下,当检索不到相关信息或知识库中没有相关信息时,大模型会产生幻觉来填补空白。为了解决这个问题,WikiChat通过汇总和过滤检索到的信息,而不是直接生成响应。同时,研究人员还教导了LLM理解时间背景,以及在必要时让系统说「我不知道」。
通过结合大模型和维基百科数据,研究人员成功地提高了聊天机器人的性能。WikiChat的成功表明,维基百科数据在大模型训练中发挥了重要作用,通过检索增强生成的方法,可以有效解决大模型的幻觉问题,提高模型的事实准确性和对话性能。
- 0000
- 0000
- 0000


 0000
0000- 0000


