摩根大通宣布推出用于多模态文档理解的DocLLM
站长网2024-01-03 14:37:572阅
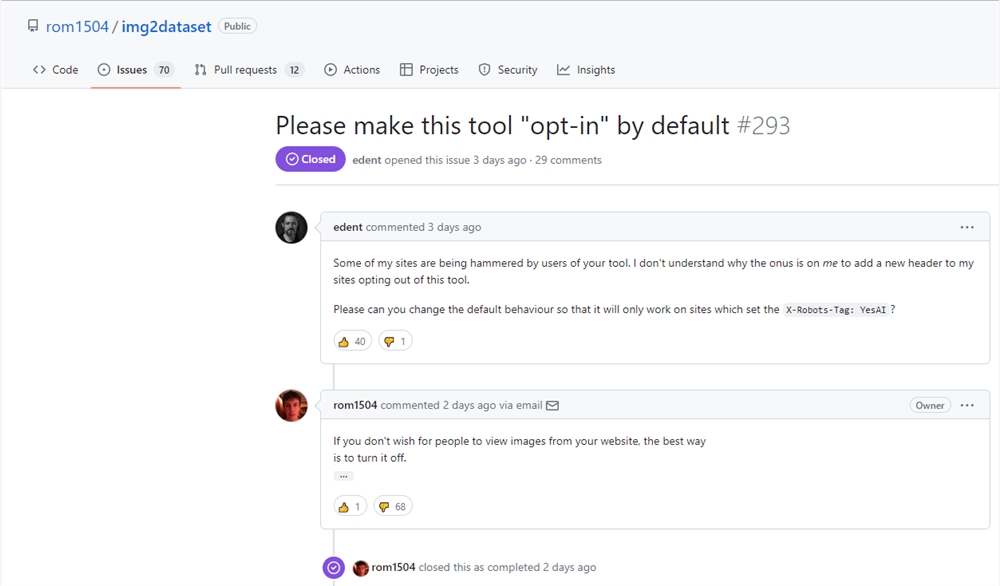
站长之家(ChinaZ.com)1月3日 消息:近日,摩根大通推出了DocLLM,这是一种为多模态文档理解而设计的生成式语言模型。DocLLM作为LLM的轻量级扩展,用于分析企业文档,涵盖了形式、发票、报告、合同等在文本和空间模态交汇处具有复杂语义的文档。
与现有的多模态LLM不同,DocLLM策略性地避免了昂贵的图像编码器,专注于边界框信息,以融入空间布局结构。该模型引入了一个分离的空间注意机制,通过将经典变压器中的注意机制分解为一组分离的矩阵。
DocLLM通过采用一个以学习填充文本片段为重点的预训练目标,来处理视觉文档中的不规则布局和异构内容。
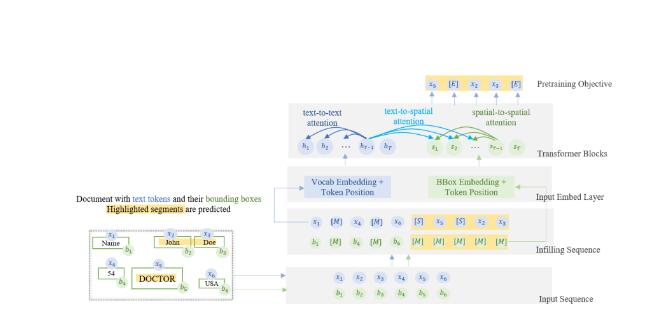
该模型具有一个分离的空间注意机制,促进文本和布局模态之间的交叉对齐,以及一个擅长有效处理不规则布局的填充预训练目标。
在预训练DocLLM时,数据来自两个主要来源:IIT-CDIP测试集1.0和DocBank。前者包括与上世纪90年代烟草行业的法律诉讼相关的500多万份文件,而后者包括50万份具有独特布局的文件。
对各种文档智能任务进行广泛评估显示,DocLLM在16个已知数据集中有14个的性能优越于最先进的LLM。该模型在4个设置中对先前未见数据集的强大泛化能力表现出色。
可见,未来摩根大通将以轻量级方式将视觉融入DocLLM,并进一步增强其能力的承诺。
论文地址:https://arxiv.org/pdf/2401.00908.pdf
0002
评论列表
共(0)条相关推荐


 0000
0000- 0002

 0000
0000- 0000
 0000
0000