微软研究人员推出WaveCoder:增强指令调优与精炼数据生成
划重点:
1. WaveCoder模型通过广泛而多才的增强指令调优,在不同的代码相关任务上表现出色。
2. 引入CodeOcean数据集,包含4个通用代码相关任务的20,000个指令实例,旨在增强指令调优的效果并提高模型的泛化能力。
3. 提出了基于LLM的生成器-鉴别器数据处理框架,通过对开源代码的分类生成多样、高质量的指令数据。
近期的研究表明,通过在高质量指令数据集上进行微调,生成的模型可以在广泛的任务上展现出色的能力。然而,现有的指令数据生成方法通常会产生重复数据,并且在数据质量上不够可控。
微软研究人员最新研究通过将指令数据分类为4个与代码相关的任务,并提出了基于LLM的生成器-鉴别器数据处理框架,从开源代码中生成多样、高质量的指令数据,从而扩展了指令调优的泛化能力。
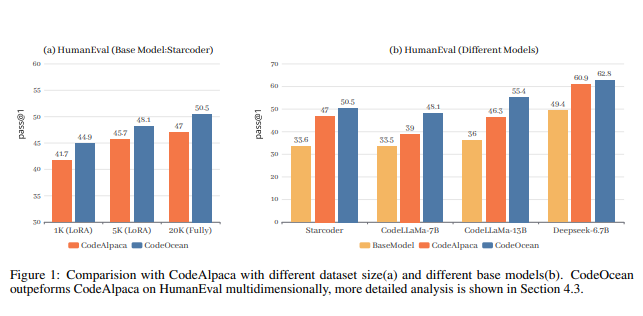
为了验证这一方法,研究人员引入了CodeOcean数据集,其中包含20,000个指令实例,涵盖了4个通用的代码相关任务,旨在增强指令调优的效果并提高模型的泛化能力。随后,研究人员提出了WaveCoder模型,这是一个经过广泛而多才的指令调优的Code LLM,专为增强指令调优而设计。实验证明,WaveCoder模型在相同微调规模下在不同的代码相关任务上优于其他开源模型,并在以往的代码生成任务中表现出高效性。
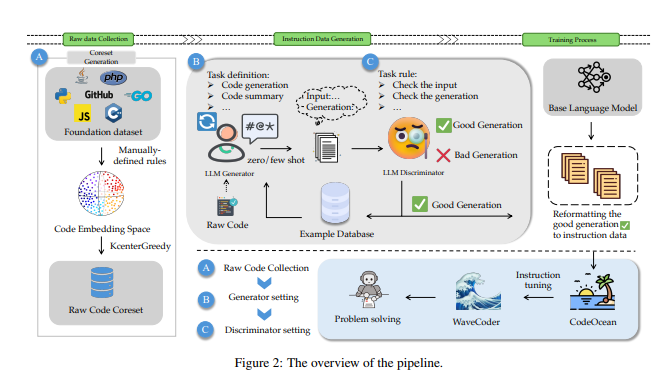
为了更好地生成指令数据并控制数据质量,研究中提出了基于LLM的生成器-鉴别器框架。该框架通过对开源代码进行分类生成更具多样性和高质量的指令数据。在训练过程中,通过生成和鉴别,该方法使数据生成过程更具定制性和可控性。文章详细介绍了从收集原始代码到生成指令数据再到训练模型的整个流程,强调了提出的方法在提高代码LLM性能方面的重要贡献。
该研究引入了多任务指令数据方法、CodeOcean 和 WaveCoder 模型来增强 Code LLM 的泛化能力。所提出的 LLM 生成器-鉴别器框架被证明可以有效生成真实的、多样化的指令数据,有助于提高各种代码相关任务的性能。未来的工作可能会探索不同任务和更大数据集之间的相互作用,以进一步增强单任务性能和泛化能力。
论文网址:https://arxiv.org/pdf/2312.14187.pdf
- 0000
- 0000
- 0001
- 0000

 0000
0000