文本到视频生成框架TF-T2V:可显著提升可扩展性与性能
# 本文概要
- TF-T2V介绍了一种创新性的文本到视频生成框架,通过独特的设计实现了卓越的可扩展性和性能提升。
- 该框架采用文本无关视频,解决了训练先进模型所需的大规模标注视频文本数据集的困难,为文本到视频生成领域带来新的可能性。
- TF-T2V的双分支结构,分别关注空间外观生成和动态运动合成,使其能够生成高质量、连贯的视频,通过引入时间一致性损失进一步提升了视频的流畅性。
在人工智能和计算机视觉领域,基于书面描述生成视频的研究引起了广泛关注。这项创新技术将创造力和计算相结合,具有在电影制作、虚拟现实和自动内容生成等领域的潜在应用。
然而,这一领域的主要障碍之一是训练先进模型所需的大规模标注视频文本数据集。创建这些数据集的过程既费时又资源密集,限制了更复杂的文本到视频生成模型的发展。传统上,文本到视频生成方法主要依赖于视频文本数据集,通常将时间块引入模型(如潜在2D-UNet),通过这些数据集进行训练以生成视频。然而,这些数据集的局限性导致难以实现无缝的时间过渡和高质量的视频输出。
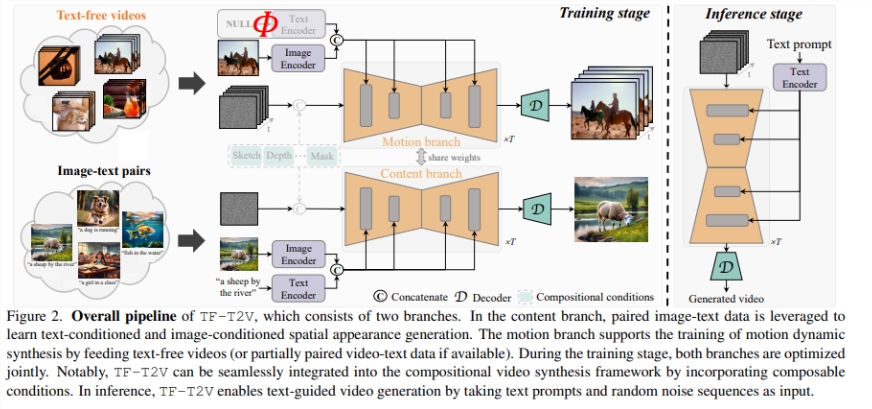
为解决这些挑战,来自华中科技大学、阿里巴巴集团、浙江大学和蚂蚁集团的研究人员引入了TF-T2V,这是一种文本到视频生成的先驱性框架。该方法在使用文本无关视频方面独具特色,避免了对大量视频文本对数据集的需求。该框架分为两个主要分支:专注于生成视频的空间外观和运动动态合成。
TF-T2V的内容分支专注于生成视频的空间外观,优化生成内容的视觉质量,确保视频既真实又具有视觉吸引力。与此同时,运动分支被设计为从文本无关视频中学习复杂的运动模式,从而增强生成视频的时间连贯性。TF-T2V的一个显著特点是引入了材料连贯性损失,这个创新组件对于确保帧之间的平滑过渡至关重要,显著提高了视频的流畅性和连贯性。
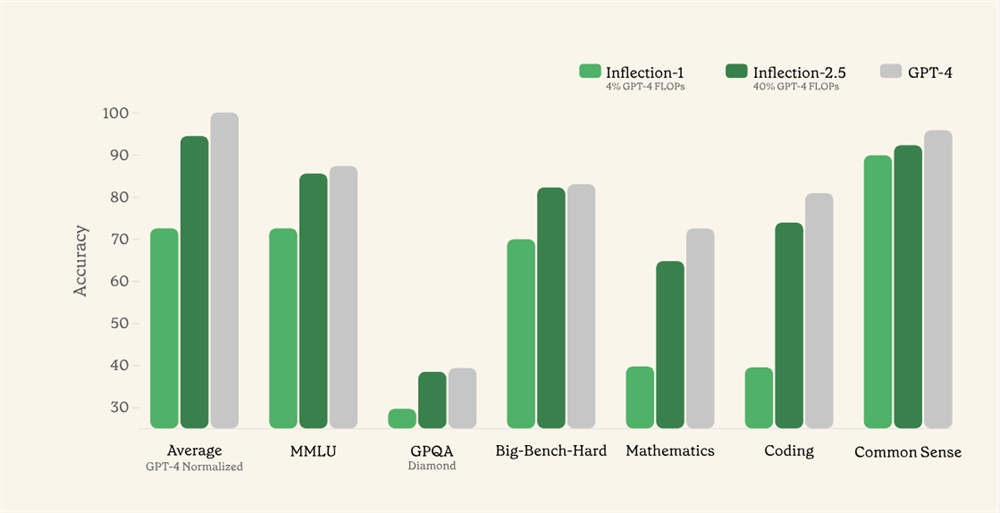
在性能方面,TF-T2V取得了显著的成果。该框架在关键性能指标如Frechet Inception Distance(FID)和Frechet Video Distance(FVD)上取得了显著的改进。这些改进表明视频生成的保真度更高,运动动态更准确。TF-T2V不仅在合成连续性方面超越了其前身,还在视觉质量方面设立了新的标准。这一进展通过一系列全面的定量和定性评估得以证明,展示了TF-T2V相对于该领域现有方法的卓越性。
最后,TF-T2V框架具有几个关键优势:
- 创新地利用文本无关视频,解决了该领域普遍存在的数据稀缺问题。
- 双分支结构,分别关注空间外观和运动动态,生成高质量、连贯的视频。
- 引入时间一致性损失显著提升了视频过渡的流畅性。
- 大量评估证明TF-T2V在生成比现有方法更逼真、连贯的视频方面具有优越性。
这项研究标志着文本到视频生成领域的重要进展,为视频合成的更可扩展和高效方法铺平了道路。这项技术的影响远不止于当前应用,还为未来媒体和内容创作提供了令人兴奋的可能性。
论文网址:https://arxiv.org/abs/2312.15770
- 0000
- 0002
- 0000
- 0000
- 0000