InternVL:60亿参数视觉语言基础模型填补多模态AGI的差距
划重点:
多模态AGI的关键突破:InternVL模型填补了视觉和视觉语言基础模型在多模态AGI系统中的发展差距。
创新的规模和对齐策略:InternVL通过将视觉基础模型扩展到60亿参数,实现了对LLM的更全面、有效的整合。
性能卓越的多样性:在32个通用视觉语言基准测试中,InternVL在图像分类、文本检索、图像字幕等任务上优于现有方法,展现了其卓越的视觉能力。
近期,人工智能领域一直将视觉和语言的无缝整合作为关注焦点,特别是在大型语言模型(LLMs)的出现下,该领域取得了显著进展。然而,对于多模态AGI系统而言,发展视觉和视觉语言基础模型仍有待迎头赶上。为填补这一差距,来自南京大学、OpenGVLab、上海人工智能实验室、香港大学、香港中文大学、清华大学、中国科技大学和SenseTime Research的研究人员提出了一种创新的模型——InternVL。该模型扩大了视觉基础模型的规模,并使其适应通用的视觉语言任务。
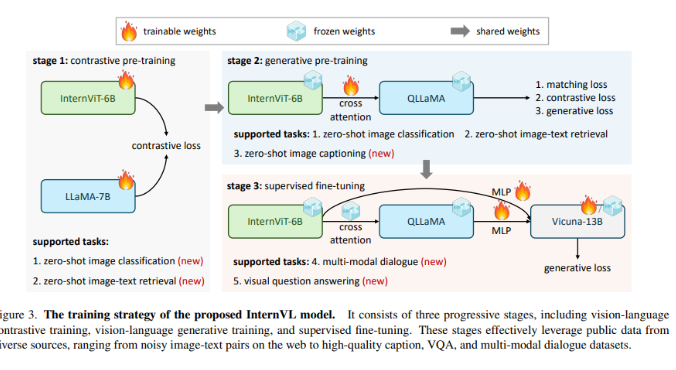
InternVL解决了人工智能领域一个关键问题:视觉基础模型和LLMs之间的发展速度差异。现有模型通常使用基本的“黏合层”来对齐视觉和语言特征,导致参数规模和表示一致性不匹配,这可能阻碍LLMs的充分潜力。
InternVL的方法独特而强大。该模型采用了大规模视觉编码器InternViT-6B和具有80亿参数的语言中间件QLLaMA。该结构具有双重作用:作为感知任务的独立视觉编码器,它与语言中间件协同工作,用于复杂的视觉语言任务和多模态对话系统。模型的训练采用了渐进对齐策略,从对大量嘈杂的图像文本数据进行对比学习开始,然后转向对更精细数据进行生成学习。这一渐进的方法在各种任务中始终提高了模型的性能。
InternVL通过在32个通用视觉语言基准测试中超越现有方法,展示了其在图像和视频分类、图像和视频文本检索、图像字幕、可见问题回答以及多模态对话等各种任务中的卓越能力。这种多样性的能力归功于与LLMs对齐的特征空间,使得该模型能够以出色的效率和准确性处理复杂任务。
InternVL的关键性能方面包括:
该模型可作为独立的视觉编码器或与语言中间件结合,适用于各种任务。InternVL通过将视觉基础模型扩展到60亿参数,创新性地解决了参数规模不匹配的问题,从而更全面、有效地与LLMs整合。在32个通用视觉语言基准测试中取得的最先进性能突显了其先进的视觉能力。在图像和视频分类、图像和视频文本检索、图像字幕、可见问题回答以及多模态对话等任务中表现出色。与LLMs对齐的特征空间增强了其与现有语言模型的无缝整合能力,进一步拓宽了应用范围。
这项研究在以下几个方面取得了突破:
InternVL是多模态AGI系统中的一大飞跃,填补了发展视觉和视觉语言基础模型的关键差距。其创新的规模和对齐策略赋予了它多样性和强大的能力,使其在各种视觉语言任务中表现卓越。
该研究有助于推动多模态大型模型的发展,潜在地重塑人工智能和机器学习的未来格局。
项目体验网址:https://top.aibase.com/tool/internvl
论文网址:https://arxiv.org/abs/2312.14238
- 0000

 0000
0000- 0000
- 0000
- 0000


