快手开源KwaiAgents系统 性能超越GPT-3.5
要点:
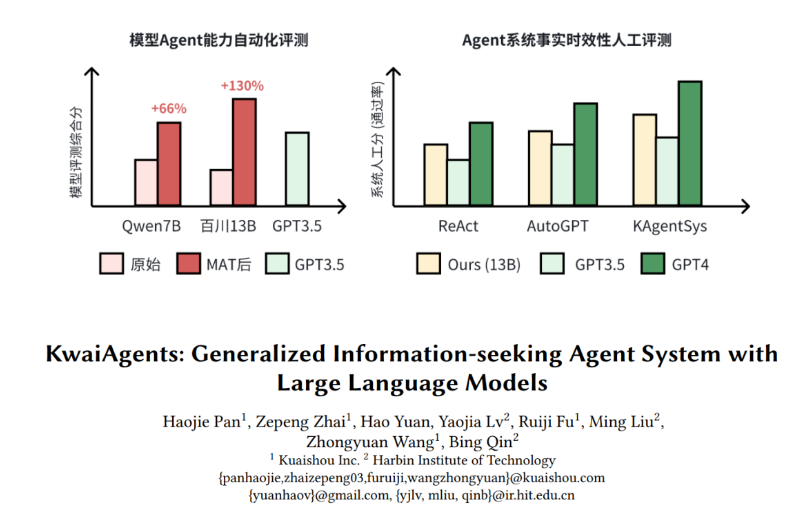
1. 快手与哈尔滨工业大学联合研发的「KwaiAgents」系统实现了7B/13B模型的开源,超越了GPT-3.5的效果。
2. 「KwaiAgents」包含轻量级AI Agents系统(KAgentSys-Lite)、具有通用能力的大模型(KAgentLMs)、以及开箱即用的自动化评测Benchmark(KAgentBench)。
3. 通过Meta-Agent Tuning(MAT)方法,模型在训练中引入更多Agent Prompt模板,提升大模型在任务规划、工具使用、反思等能力,从而达到超越效果。
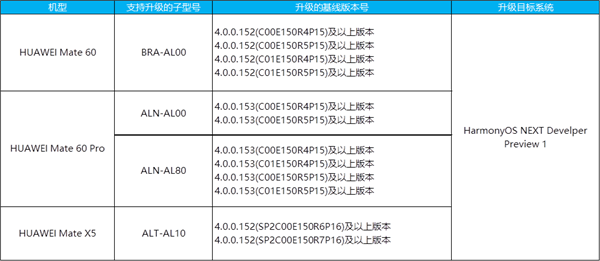
近日,快手联合哈尔滨工业大学成功开源了「KwaiAgents」系统,实现了7B/13B模型的超越效果。这一成果的背后,是通过Meta-Agent Tuning(MAT)方法提升大模型的通用能力。整个项目包含了系统、模型、以及评测三个方面的内容,并通过GitHub完全开源,为研究者和开发者提供了极大的便利。
项目地址:https://github.com/KwaiKEG/KwaiAgents
该系统以大模型为认知内核,配以记忆机制和工具库,形成迭代式自动化系统。记忆机制包含知识库、对话和任务历史三类记忆,通过混合向量检索和关键词检索技术,在每一轮对话中检索所需信息。工具集包含事实性增强工具,异构的搜索和浏览机制能够汇集多个来源的知识,包括网页、文本百科和视频百科。自动化Loop中,系统在一轮对话中接收问题,进行记忆的更新和检索,调用大模型进行任务规划,根据需要调用工具,最后综合历史信息给出回答。
为避免训练中单一模板引起的过拟合问题,团队提出了MAT方法。该方法分为两阶段:模板生成阶段和指令微调阶段。在模板生成阶段,通过设计Meta-Agent,生成实例化的Agent Prompt模板,候选结果与开源模板进行对比打分,从而筛选出高质量的Agent Prompt模板库。在指令微调阶段,基于上万的模板构建了超过20万的Agent调优指令微调数据。通过这一方法,模型在任务规划、工具使用、反思等方面的能力得到提升,同时避免了过度依赖单一模板的问题。
KAgentBench通过人工精细化标注的数据,提供开箱即用的Agent能力自动化评测Benchmark。该Benchmark涵盖不同种类的能力构造输入,每个query配备多个模板和多个人工编辑的真实回答,综合评测准确性和泛化性。评测结果显示,通过MAT调优后,7B-13B模型在各项能力上均有显著提升,超越了GPT-3.5的效果。
团队表示,AI Agents是一条具有潜力的道路,未来将持之以恒地沉淀核心技术,并积极探索Agents技术与快手业务的结合,尝试更多有趣、有价值的创新应用落地。这一开源项目为整个社区注入了新的活力,为研究者提供了丰富的资源和参考。
- 0000
- 0000
 0000
0000- 0000
- 0000