清华大学开发出新视觉语言模型 可更准确理解 GUI
站长网2023-12-27 15:46:220阅
清华大学智普AI的研究人员开发了一种新的视觉语言模型(VLM),名为 CogAgent。该模型专门设计用于理解和导航图形用户界面(GUI)。
CogAgent 通过采用低分辨率和高分辨率图像编码器而脱颖而出。这种双编码器系统允许模型处理和理解复杂的 GUI 元素和文本内容,这是有效 GUI 交互的关键要求。
CogAgent 的架构具有独特的高分辨率跨模块,这是其性能的关键。该模块使模型能够有效处理高分辨率输入(1120x1120像素),这对于识别小型 GUI 元素和文本至关重要。
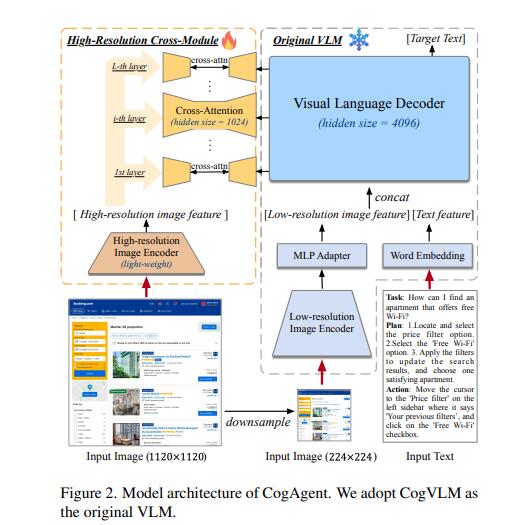
CogAgent 在各种任务中优于现有的基于 LLM 的方法,特别是在 PC 和 Android 平台的 GUI 导航方面。该模型还在多个文本丰富和一般视觉问答基准上表现优异。
这项研究的结果表明,CogAgent 代表了 VLM 的重大飞跃,特别是在涉及 GUI 的环境中。其在可管理的计算框架内处理高分辨率图像的创新方法使其有别于现有方法。该模型在不同基准测试中优异的性能表明其在自动化涉及 GUI 操作和解释的复杂任务方面的潜力。
CogAgent 的潜在应用包括:
自动化 GUI 操作,例如点击按钮、输入文本和选择菜单。提供 GUI 帮助和指导,例如解释功能和提供操作说明。开发新的 GUI 设计和交互方式。
CogAgent 仍处于早期开发阶段,但其潜在影响是巨大的。该模型有可能彻底改变我们与计算机交互的方式。
地址:https://github.com/THUDM/CogVLM
0000
评论列表
共(0)条相关推荐
- 0000
 0000
0000- 0000
- 0003
- 0000