智源研究院开源代码生成训练数据集与评测基准TACO
站长网2023-12-25 18:52:261阅
TACO 是一个专注于算法的代码生成数据集,旨在为代码生成模型提供更具挑战性的训练数据集和评测基准。
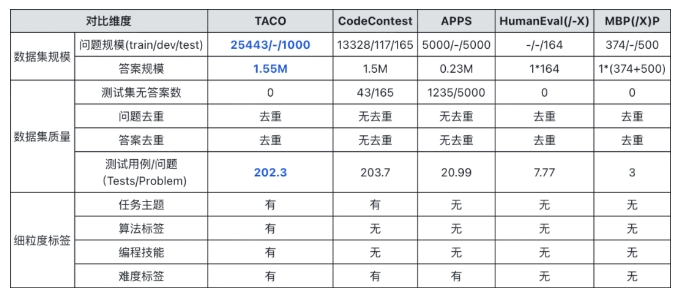
与当前主流代码评测基准相比,TACO 在数据规模、数据质量和细粒度评测方案上具有明显优势。它包括更大规模的训练集和测试集,每个题目都具备多样化的解题答案,并提供了细粒度的标签,如任务主题、算法、编程技能和难度等级。
实验结果表明,当前流行的代码生成模型在 TACO 评测中与 GPT-4存在显著差异,说明这一领域仍有巨大的提升空间。
TACO 数据集不仅提供了一个挑战性的测试方法,还能作为研究和改进模型性能的训练数据。通过社区的共同努力,可以激发更多创新的解决方案,进一步推动代码生成领域的发展。
具体特性如下:
规模更大:TACO 包括训练集(25443道题目)和测试集(1000道题目),是当前规模最大的代码生成数据集。
质量更高:TACO 数据集中的每个题目都尽可能匹配多样化的解题答案,答案规模高达155万条,确保训练时模型不易过拟合以及评测结果的有效性。
提供细粒度标签:TACO数据集中每个题目均包含任务主题、算法、技能及难度等细粒度标签,为代码生成模型的训练与评测更精确的参考。
TACO 开源地址:
论文:https://arxiv.org/abs/2312.14852
智源开放数据仓库:https://data.baai.ac.cn/details/BAAI-TACO
GitHub:https://github.com/FlagOpen/TACO
Hugging Face:https://huggingface.co/datasets/BAAI/TACO
新鲜AI产品点击了解:https://top.aibase.com/
0001
评论列表
共(0)条相关推荐
- 0000
- 0000
- 0000
- 0000

 0001
0001