AI视野:Runway推出Gen-2视频合成功能;Midjourney支持生成文字;实时生图技术StreamDiffusion开源;智源开源Emu2模型
🤖📱💼AI应用
Runway推出Gen-2视频合成功能
地址最新功能支持将多个Gen2生成的视频合成到一个场景中,用户可轻松创造丰富的场景内容视频,类似于Photoshop的图层功能。
地址:https://top.aibase.com/tool/runway
【AiBase提要】:
🚀 Runway新功能允许用户将多个Gen2生成的视频合成,形成更为丰富的场景内容视频。
🎥 利用Gen-2合成工作流程,用户可将人物、风景、建筑等元素融合到一个场景中,类似于Photoshop的图层功能。
🎨 合成工作流程包括定制运动、编辑视频、覆盖主题视频在生成的背景视频上,并通过调整色彩等手段使合成更加无缝和协调。
Midjourney能生成文字了
Midjourney发布V6版本,图像更真实、文字生成功能问世,创始人表示是团队从头开始训练的第三个模型,更新包括图像优化、文字处理等5大升级。

【AiBase提要】
🖼️ 图像升级:V6版本图像更真实,细节处理更细腻,人物和风景图表现出众。
📝 文字生成功能:新增基础文字绘制功能,用户可以对简单文字进行处理。
⚙️ 技术升级:V6带来更精确、更长的提示响应,改进了连贯性和模型知识,训练历时9个月。
谷歌Duet AI推出移除背景功能
谷歌最新推出的Duet AI技术可使用户在Google幻灯片和绘图中方便地移除图片背景,旨在提升用户编辑效率和体验。
【AiBase提要:】
🖼️ 移除背景功能: 用户上传图片至Google幻灯片或绘图,通过右键点击或工具栏/格式菜单选择,即可轻松移除图片背景,提高编辑效率。
🔍 简便操作: 整个过程仅需几秒钟,让用户迅速保留主题,但需手动裁剪以避免缩小图片。
🌐 拓展AI应用: 新功能将作为Workspace Labs的一部分开放,谷歌继续扩展其AI技术应用范围,提供更高效和直观的编辑工具。
ComfyUI Portrait Master2.2版本发布
ComfyUI 最新发布了 Portrait Master2.2版本,引入全新姿势库,并提供与 Portrait Master 兼容的工作流程文件。该版本集成了放大器和两个 ControlNet,进一步提升了姿势管理和控制功能。

项目地址:https://github.com/florestefano1975/comfyui-portrait-master/
【AiBase提要:】
🎨 精准控制外貌特征: Portrait Master 提供丰富参数,可调整每个特征的权重,实现对生成图像的精细控制。
🔄 智能提示生成: 用户可通过简单命令定义生成人像的提示,包括外貌和姿态,支持正向和负向提示。
🚀 灵活安装与更新: 提供便捷的安装和更新方式,通过 ComfyUI Manager 或命令行手动安装,保持功能和性能的最新版本。
Privado推出开源LLM聊天应用MuroChat
Privado.ai推出的开源LLM聊天应用MuroChat旨在解决基于大型语言模型的聊天机器人引入的数据隐私风险,通过自动检测和删除敏感数据加强企业数据保护。
Privado体验网址:https://top.aibase.com/tool/privado
【AiBase提要:】
🔸 Privado.ai推出开源的LLM聊天应用MuroChat,专注于解决聊天机器人引入的数据隐私风险。
🔸 MuroChat通过集成大型语言模型,自动检测和删除敏感数据,满足企业组织的数据保护需求。
🔸 特性包括数据防火墙、单一登录支持、本地聊天历史记录等,旨在提供全面的数据安全解决方案。
👨💻💡🎯聚焦开发者
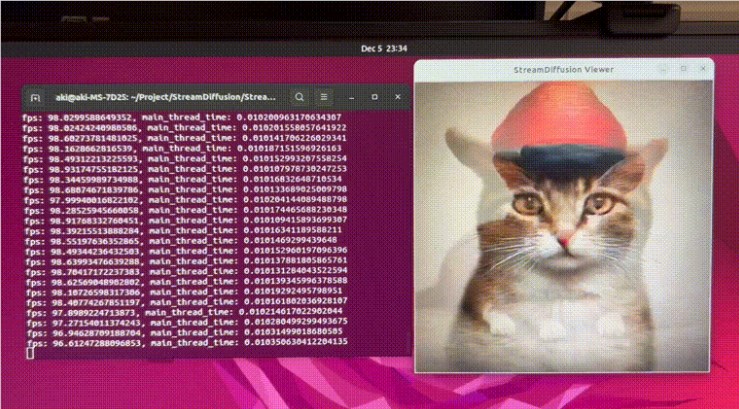
StreamDiffusion开源
StreamDiffusion是基于LCM和SDXL Turbo技术的开源项目,每秒可生成110张图像,为实时图像生成产品开发提供强大资源。
项目地址:https://top.aibase.com/tool/streamdiffusion
【AiBase提要:】
🚀 StreamDiffusion基于LCM和SDXL Turbo技术,每秒生成110张图像。
🔧 项目支持多种模型和输出帧率,提供显著性能增强。
🔄 除高性能外,通过流程优化、指导机制改进等技术,为实时图像生成者提供有价值的开源资源。
Stable AI向开发者开放视频生成模型SVD的API服务
稳定AI公司发布基于图像的视频生成模型SVD,并通过API服务开放,尽管使用备受争议的LAION-5B数据集进行训练。
SVD体验网址:https://top.aibase.com/tool/stable-video-diffusion
【AiBase提要:】
🚀 SVD模型上线: 稳定AI发布基于图像的视频生成模型SVD,通过API服务向开发者提供,可整合到各应用领域。
🤔 数据争议: 使用LAION-5B数据集引发关切,该数据集涉及儿童性虐待材料,导致争议,但SVD在视频生成质量上仍领先。
🌐 竞争态势: 稳定AI计划推出用户界面,与竞争对手Runway和Pika Labs竞争,提供多样化视频生成功能。
魔搭社区开源多模态对齐统一框架OneLLM
OneLLM是一种多模态对齐的框架,利用通用编码器和统一的投影模块与大型语言模型对齐多模态输入,支持视频、音频、图像等多种数据类型。
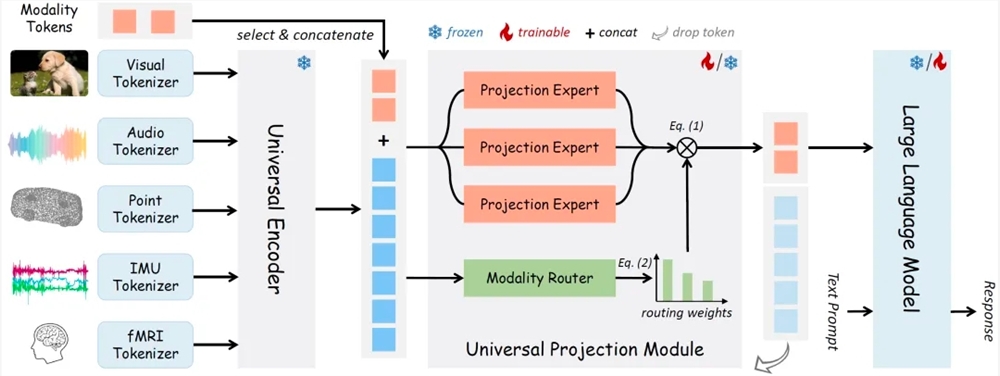
【AiBase提要】
🔍 多模态对齐框架: OneLLM采用通用编码器和统一投影模块,实现视频、音频、图像等多模态输入的对齐。
🔄 模态切换实现: 使用modality tokens实现在不同模态之间的灵活切换。
📊 强大性能验证: 实验证明OneLLM在视频-文本、音频-视频-文本等任务中优于现有方法,表现出较强的零样本能力。
Github代码链接:
https://github.com/csuhan/OneLLM
模型权重链接:
https://modelscope.cn/models/csuhan/OneLLM-7B
模型创空间:
https://modelscope.cn/studios/csuhan/OneLLM
📰🤖📢AI新鲜事
研究揭示:谷歌Gemini Pro在基准测试中落后于免费ChatGPT
谷歌Gemini Pro在卡内基梅隆大学的研究中未能达到预期水平,基准测试中表现不如GPT-3.5,甚至远远不及GPT-4,与谷歌发布会上的信息相矛盾。
【AiBase提要】
📉 性能落后: Gemini Pro在基准测试中远不如GPT-3.5,研究结果与谷歌发布的信息相矛盾,强调中立基准测试机构的必要性。
🔄 信息矛盾: Gemini团队声称即将推出的"Ultra"版本将超越GPT-4,但研究发现谷歌已对Ultra的基准结果进行操纵。
🧐 表现差异: Gemini Pro在数学推理、多选题等方面表现不佳,对自身基准的依赖不足以可靠衡量语言模型性能,强调仅依赖自我报告的基准测试不可靠。
苹果AI新突破:在iPhone上部署大型语言模型成为可能
苹果AI研究人员通过创新的闪存利用技术,成功将大型语言模型(LLMs)部署到内存有限的iPhone等设备上,为更先进的Siri功能、实时语言翻译和复杂AI驱动功能打开了新的可能性。
【AiBase提要】
🔍 内存限制挑战解决:苹果AI团队开发了一种创新的闪存利用技术,巧妙绕过iPhone内存限制,成功在设备上部署大型语言模型。
🚀 AI效率突破:通过窗口化技术和行列捆绑技术,AI模型在闪存中运行的规模达到iPhone可用内存的两倍,提高处理速度4-5倍(CPU)和20-25倍(GPU)。
🌐 未来AI应用展望:这一突破为iPhone打开了新的AI应用可能性,包括更先进的Siri功能、实时语言翻译以及在摄影和增强现实中的复杂AI驱动功能。
OpenAI参投,法律科技公司Harvey获5.7亿元融资
由OpenAI参与投资的法律科技公司Harvey成功融资5.7亿元,基于OpenAI的GPT-4系列模型,为律师提供深度定制ChatGPT助手,与全球大律所普华永道达成战略合作。
【AiBase提要:】
⚖️ Harvey宣布获得8000万美元B轮融资,估值达7.15亿美元,由凯鹏华盈、红杉资本、OpenAI初创基金等投资。
🌐 基于OpenAI的GPT-4系列模型,Harvey为律师提供深度定制ChatGPT助手,在法律领域取得优异成绩,全球大律所普华永道成为核心战略合作伙伴。
🌐 Harvey积极扩大市场影响力,与普华永道、OpenAI技术合作,助力开发专有法律ChatGPT助手,应用于法律、税务、人力资源等多个领域。
一位中国教授使用AI创作科幻小说,荣获全国大奖
一位清华大学教授计划创作关于元宇宙和人形机器人的科幻小说,最终由人工智能完成整本书,名为《记忆之地》,赢得国家科幻奖项。
【AiBase提要】
📚 清华教授使用AI撰写的《记忆之地》荣获国家科幻奖项。
🧠 故事由AI生成,以元宇宙探险家为主角,探讨失忆与人工智能的复杂关系。
🤖 虽受赞誉,但评审指出AI写作或许对文学语感带来挑战。
🤖📈💻💡大模型动态
智源开源Emu2模型
智源研究院推出Emu2,采用自回归生成式多模态预训练,在多模态上下文学习方面取得显著突破。Emu2在少样本多模态理解任务上表现出色,超越了Flamingo-80B和IDEFICS-80B。

AiBase提要:
🚀 Emu2采用大规模自回归生成式多模态预训练,在多模态上下文学习方面取得显著突破。,
💡 Emu2在少样本多模态理解任务上超越主流模型,包括Flamingo-80B和IDEFICS-80B。,
🌐 Emu2是目前最大的开源生成式多模态模型,分别推出Emu2-Chat和Emu2-Gen,成为性能最强的视觉理解和生成模型。
项目:https://baaivision.github.io/emu2/
模型:https://huggingface.co/BAAI/Emu2
代码:https://github.com/baaivision/Emu/Emu2
Demo:https://huggingface.co/spaces/BAAI/Emu2
论文:https://arxiv.org/abs/2312.13286
Meta发布全新AI翻译大模型
Meta发布全新AI翻译大模型,实时语音转换延迟不超过2秒,可模仿语气、语速、情绪,解决了“莫得感情”问题。模型系列包括SeamlessExpressive、SeamlessStreaming、SeamlessM4T v2和Seamless。
【AiBase提要:】
🚀 Meta发布全新AI翻译大模型,实现实时语音转换,模仿语气与情感。
🌐 模型系列包括SeamlessExpressive、SeamlessStreaming、SeamlessM4T v2和Seamless。
🔐 采用非自回归架构、核心算法EMMA,引入“毒性缓解”和音频水印技术,提高翻译质量和安全性。
- 0000
- 0000
- 0005
- 0001
 0000
0000