智源研究院开源发布新一代生成式多模态基础模型 Emu2
2023年12月21日,智源研究院发布了新一代多模态基础模型 Emu2。Emu2通过大规模自回归生成式多模态预训练,显著推动了多模态上下文学习能力的突破。
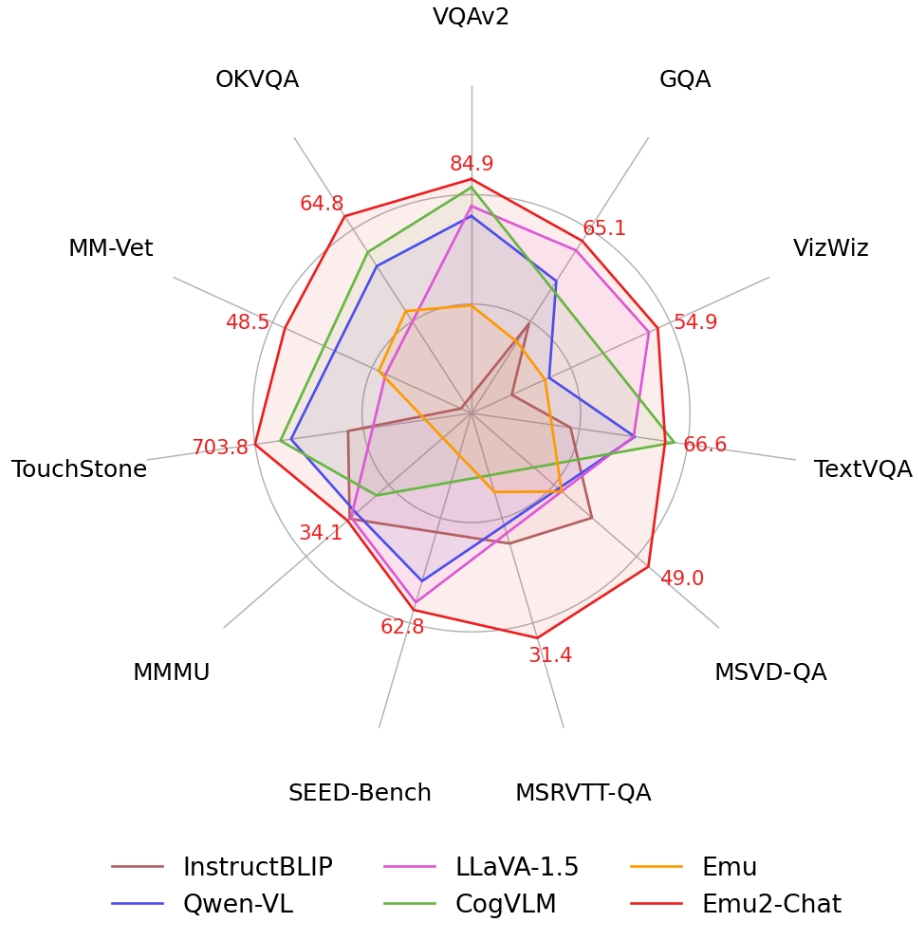
Emu2在少样本多模态理解任务上表现出色,超越了主流多模态预训练大模型 Flamingo-80B 和 IDEFICS-80B。在 VQAv2、OKVQA、MSVD、MM-Vet、TouchStone 等多个少样本理解、视觉问答、主体驱动图像生成任务上,Emu2取得了最优性能。
Emu2是目前最大的开源生成式多模态模型,基于 Emu2微调的 Emu2-Chat 和 Emu2-Gen 模型分别是目前开源的性能最强的视觉理解模型和能力最广的视觉生成模型。Emu2-Chat 可以精准理解图文指令,实现更好的信息感知、意图理解和决策规划。Emu2-Gen 可以接受图像、文本、位置交错的序列作为输入,实现灵活、可控、高质量的图像和视频生成。
Emu2使用了更简单的建模框架,并训练了从编码器语义空间重建图像的解码器,将模型规模化到37B 参数。Emu2采用大量图、文、视频的序列,建立了基于统一自回归建模的多模态预训练框架,将图像、视频等模态的 token 序列直接和文本 token 序列交错在一起输入到模型中训练。
通过对多模态理解和生成能力的评测,Emu2在少样本理解、视觉问答、主体驱动图像生成等任务上取得了最优性能。在16-shot TextVQA 等场景下,Emu2相较于 Flamingo-80B 超过12.7个点。在 DreamBench 主体驱动图像生成测试上,Emu2比之前的方法取得了显著提升。
Emu2具备全面且强大的多模态上下文学习能力,可以照猫画虎地完成多种理解和生成任务。Emu2-Chat 经过对话数据指令微调,可以精准理解图文指令,完成多模态理解任务。Emu2-Gen 可以接受任意 prompt 序列作为输入,生成高质量的图像和视频。
Emu2的训练方法是在多模态序列中进行生成式预训练,使用统一的自回归建模方式。相比于 Emu1,Emu2采用了更简单的建模框架,训练了更好的解码器,并将模型规模化到37B 参数。
项目:https://baaivision.github.io/emu2/
模型:https://huggingface.co/BAAI/Emu2
代码:https://github.com/baaivision/Emu/Emu2
Demo:https://huggingface.co/spaces/BAAI/Emu2
论文:https://arxiv.org/abs/2312.13286
- 0000

 0003
0003- 0001
- 0000
- 0000