OpenAI公布ChatGPT安全框架 以保障AI安全
OpenAI 是 ChatGPT 的开发者,他们制定了应对人工智能可能带来的严重危险的计划。该框架包括使用 AI 模型的风险 “记分卡” 来衡量和跟踪潜在危害的各种指标,以及进行评估和预测。OpenAI 表示将根据新数据、反馈和研究不断完善和更新框架。
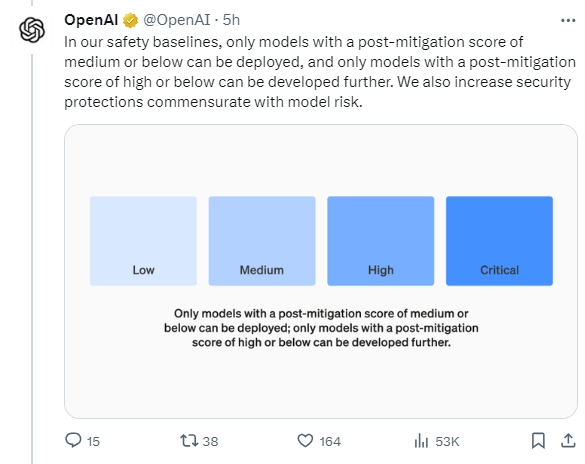
该公司的 “应对” 团队(Preparedness Framework)将雇佣人工智能研究人员、计算机科学家、国家安全专家和政策专业人员来监测技术,并不断测试并警告公司,如果他们认为任何人工智能能力变得危险。该团队位于 OpenAI 的 “安全系统” 团队和 “超对齐” 团队之间。前者致力于解决人工智能中的问题,例如注入种族主义偏见,而后者研究如何确保在想象中的人工智能完全超过人类智能的未来中,人工智能不会对人类造成伤害。
据悉,“应对” 团队正在招聘来自人工智能领域之外的国家安全专家,帮助 OpenAI 了解如何应对重大风险。他们正在与包括美国国家核安全管理局在内的组织展开讨论,以确保公司能够适当地研究人工智能的风险。
该公司还将允许来自 OpenAI 之外的 “合格、独立的第三方” 测试其技术。

OpenAI 的 “应对框架” 与其主要竞争对手 Anthropic 的政策形成了鲜明对比。
Anthropic 最近发布了其 “负责任扩展政策”(Responsible Scaling Policy),该政策定义了特定的 AI 安全级别和相应的开发和部署 AI 模型的协议。两个框架在结构和方法论上存在显著差异。Anthropic 的政策更加正式和规范,直接将安全措施与模型能力联系起来,并在无法证明安全性时暂停开发。OpenAI 的框架更加灵活和适应性强,设定了触发审查的一般风险阈值而不是预定义的级别。
专家表示,这两个框架都有其优点和缺点,但 Anthropic 的方法可能在激励和执行安全标准方面更具优势。一些观察人士还认为,OpenAI 在面对对 GPT-4等模型的快速和激进部署后,正在赶上安全协议方面的工作。Anthropic 的政策之所以具有优势,部分原因是它是主动开发而不是被动应对。
无论差异如何,这两个框架都代表了人工智能安全领域的重要进展。随着人工智能模型变得越来越强大和普及,领先实验室和利益相关者之间在安全技术上的合作和协调现在是确保人工智能对人类的有益和道德使用的关键。
- 0000
- 0000
- 0000
- 0000
- 0003