通用物体级基础模型GLEE:增强图像和视频分析
**划重点:**
1. 🧠 GLEE是一种通用物体级别基础模型,由华中科技大学、字节跳动和约翰斯·霍普金斯大学的研究人员共同推出,突破了当前视觉基础模型的限制,提供准确而全面的物体级信息。
2. 🎓 GLEE以其在各种任务中表现卓越的通用性而闻名,无需特定任务适应即可在不同对象感知任务中定位和识别物体,同时集成大型语言模型以提供多模态研究的通用物体级信息。
3. 🚀 该模型展现出出色的灵活性和卓越的泛化能力,特别在零样本传输场景中表现突出。通过整合各种数据源,包括自动标记的大量数据,GLEE不仅实现了可扩展的数据集扩展,还提高了零样本能力,成为未来图像和视频任务的基础模型。
近日,来自华中科技大学、字节跳动和约翰斯·霍普金斯大学的研究人员推出了一款名为GLEE的全新通用物体级别基础模型,为图像和视频分析带来了全新的可能性。这一技术突破依赖深度学习的神奇,使计算机视觉系统能够像虚拟侦探一样,在数字体验的画布上识别、跟踪和理解各种物体。
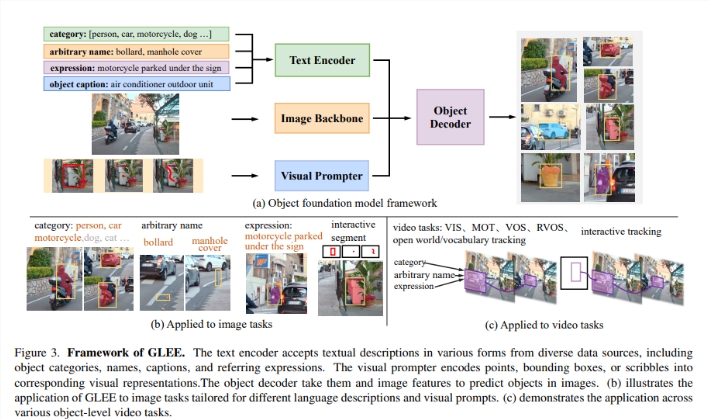
GLEE的独特之处在于其卓越的通用性,无需特定任务的适应即可在各种任务中定位和识别物体。该模型集成了图像编码器、文本编码器和视觉提示器,用于多模态输入处理和广义物体表示预测。通过在Objects365、COCO和Visual Genome等多样化的数据集上进行训练,GLEE采用统一框架,涵盖检测、分割、跟踪、定位和识别开放场景中的对象。
GLEE通过使用动态类头的MaskDINO以及相似性计算进行预测的对象解码器,经过目标检测和实例分割的预训练,联合训练实现了在各种图像和视频任务中的最先进性能。不仅如此,GLEE还展现了卓越的灵活性和强大的泛化能力,有效应对各种下游任务,无需特定任务的适应。
该模型在对象检测、实例分割、定位、多目标跟踪、视频实例分割、视频对象分割以及交互式分割和跟踪等各种图像和视频任务中均表现卓越。甚至在与其他模型集成时,GLEE仍保持着最先进性能,展示了其表示的多样性和有效性。

除了在技术上的突破,GLEE在零样本泛化方面也取得了显著进展,通过整合大量自动标记的数据进一步提升了模型的性能。作为一种基础模型,GLEE为当前视觉基础模型的局限性提供了创新性的解决方案,提供准确而通用的物体级信息。
研究的未来方向聚焦在扩展GLEE在处理复杂场景和具有长尾分布的挑战性数据集方面的能力上,以提高其适应性。此外,研究人员还探索了在训练过程中使用广泛的图像-标题对,类似于DALL-E模型,从而提高GLEE生成详细图像内容的潜力。
项目体验网址点击这里:https://top.aibase.com/tool/glee
论文网址:https://arxiv.org/abs/2312.09158
- 0000
- 0000


 0000
0000- 0000
- 0000