EPFL与苹果研究人员开源4M:跨多种模态和任务训练多模态基础模型的人工智能框架
**划重点:**
- 🌐 **多模态挑战:** 自然语言处理中训练大型语言模型(LLMs)变得流行,但在视觉领域仍需灵活可扩展的模型。
- 🤖 **4M框架:** EPFL和苹果团队提出"Massively Multimodal Masked Modeling"(4M)框架,整合Transformer技术,具备强大的跨模态能力。
- 🚀 **可扩展性与效率:**4M通过模态特定的标记器实现对各种输入模态的训练,提高兼容性、可扩展性,并通过输入和目标掩码实现高效训练。
近日,瑞士洛桑联邦理工学院(EPFL)与苹果联手推出了一项名为"Massively Multimodal Masked Modeling"(4M)的人工智能框架,旨在解决训练跨多模态视觉基础模型的挑战。尽管在自然语言处理领域,训练大型语言模型(LLMs)已经取得了显著成功,但在视觉领域,仍需要构建能够灵活处理多种输入模态和输出任务的模型。
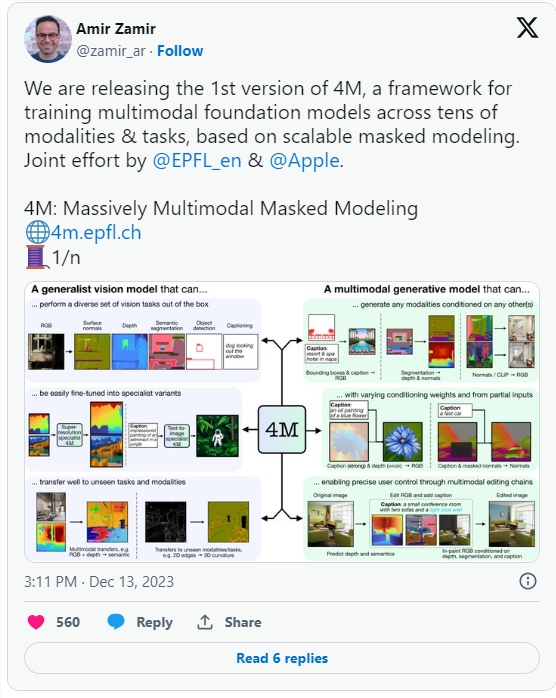
4M框架采用了一种独特的策略,通过训练单一的Transformer编码器-解码器,具备多模态的掩码建模目标。"Massively Multimodal Masked Modeling"强调了该方法在扩展到多种各异模态方面的能力。这一方法融合了掩码建模和多模态学习的最佳特性,包括强大的跨模态预测编码能力、共享场景表示以及通过迭代抽样实现生成任务的能力。
不仅如此,4M在保持高效性的同时,通过模态特定的标记器将各种格式的输入模态转换为离散标记的集合或序列,使得单一的Transformer可以同时处理文本、边界框、图片或神经网络特征等多种输入模态,实现它们的统一表示领域。
此外,4M采用了输入和目标掩码的方式,即从所有模态随机选择一小部分标记作为模型输入,另一小部分作为目标。通过将输入和目标标记的数量与模态数量解耦,防止了随着模态数量增加而导致的计算成本快速上升。通过利用CC12M和其他可用的单模态或文本-图片对数据集,使用强大的伪标签网络创建模态对齐的绑定数据,4M在不需要多模态/多任务注释的情况下,可以在不同且大规模的数据集上进行训练。
研究人员发现,4M模型不仅在多个重要的视觉任务上表现出色,而且可以进行精细调整以在未来的任务和输入模态上取得显著成果。为了训练可导向的生成模型,可以根据任何模态进行条件化,必须使用多模态的掩码建模目标。通过对4M性能影响的深入消融分析,结合该方法的简便性和通用性,研究人员认为4M在许多视觉任务和未来发展中具有巨大的潜力。
项目体验网址:https://4m.epfl.ch/
论文网址:https://arxiv.org/abs/2312.06647
- 0000
- 0000

 0000
0000- 0000
- 0005