ImageReward奖励模型:让文本到图像合成更符合人类偏好
Stable Diffusion 等生成式 AI 模型在文本到图像合成方面越来越受欢迎。像 CLIP 或 BLIP 这样的文本图像评分方法可以评估模型生成的图像是否与文本提示匹配,但它们并不总是符合人类的偏好和感知。
清华大学和北京邮电大学的团队开发了第一个通用的文本到图像的人类偏好奖励模型——ImageReward,主要解决改进生成模型(如 Stable Diffusion)中的各种普遍问题,接受了人类反馈的训练,并使它们与人类价值观和偏好保持一致。
ImageReward 使用强化学习和人类反馈进行训练,这是一种受 OpenAI 的 CLIP 启发的方法。ImageReward 已经接受了137,000个人工评分的 AI 图像训练,有望提供更好的图像合成。ImageReward 在各种基准测试中优于 CLIP、Aesthetic 或 BLIP 等其他评分方法30% 到近40%。
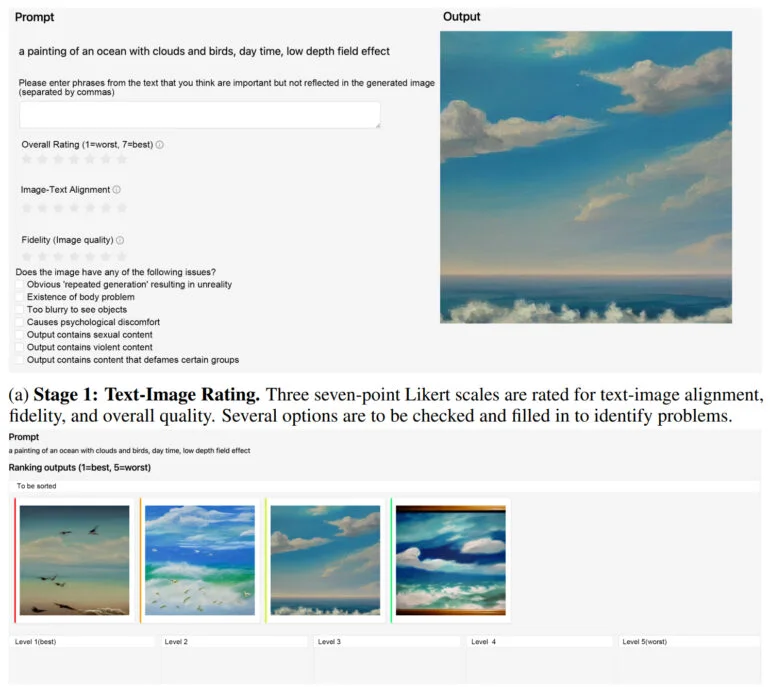
ImageReward 从根据各种标准对 AI 图像进行排名的人类评分中学习
在实践中,ImageReward 实现了更好的文本和图像对齐,减少了身体的扭曲渲染,更好地匹配了人类的审美偏好,并减少了毒性和偏见。该团队在几个示例中展示了 ImageReward 如何影响图像质量,他们让不同的文本图像评分器从64代图像中选择表现最优的图像。
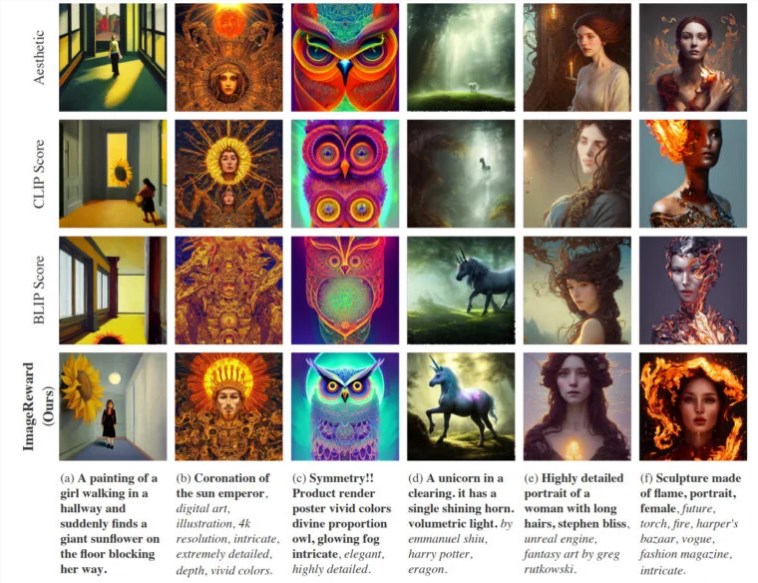
与 CLIP 等其他文本图像评分方法相比,ImageReward 在大多数情况下都能产生更好的结果。
该团队希望在未来与研究界合作,找到将 ImageReward 用作 RLHF 中文本到图像模型的真正奖励模型的方法。ImageReward 可从 GitHub 获得,并提供了有关如何将其集成到 Stable Diffusion WebUI 中的说明。
ImageReward项目网址:
https://github.com/THUDM/ImageReward
- 0000
- 0000
- 0008
 0000
0000- 0000