AI视野:OpenAI否认即将发布GPT-4.5;Stability AI推出新会员模式;DomoAI支持视频一键转动漫;阿里I2VGen-XL模型代码公布
📰🤖📢AI新鲜事
OpenAI否认即将发布GPT-4.5
OpenAI CEO Sam Altman在Reddit上辟谣称公司未计划发布GPT-4.5,否认最新语言模型的泄露,截图显示为虚假信息。
【AiBase提要】:
👥 OpenAI CEO Sam Altman否认GPT-4.5泄露,证实截图为假信息。
📅 尚不清楚OpenAI是否会发布GPT-4.5,或者直接跳至GPT-5。
🌐 OpenAI曾在2020年发布GPT-3,2023年3月发布GPT-4,同时正积极开发GPT-5。
OpenAI新研究:GPT-2能监督GPT-4
研究发现通过以GPT-2级模型为弱监督者对GPT-4进行微调,能显著提高自然语言处理任务中的泛化性能,为超级AI对齐问题提供新思路。
【AiBase提要】
🔍 创新方向: 通过小模型的弱监督控制大模型,解决超级AI对齐问题的挑战。
📈 研究结果: GPT-2级模型对GPT-4微调在语言处理任务中取得显著改进,展示了弱到强泛化的可行性。
👥 研究机会: 提供开源代码和1000万美元资助计划,鼓励研究者在超级AI对齐领域进行深入研究。
Stability AI推出新会员模式
Stability AI在充满活力的2023年推出新会员模式,以标准化商业使用,包括免费和PRO会员,同时保持对源代码和权重的开放。
【AiBase提要:】
💼 新会员模式: Stability AI推出旨在推动商业应用的新会员模式,拓展企业部署范围,让公司模型成为构建业务的基石。
💰 商业模式: 包括免费个人、PRO会员和企业定制定价,同时保持对源代码和权重的开放,注重多样化的开放方式。
🚀 未来展望: 免费个人用户也能享受会员资格带来的价值,包括提前访问新模型发布、参与公共论坛以及在Stability AI渠道上展示的机会。创始人看好新模式对初创公司和大型企业的吸引力,认为将成为稳健的收入基础。
英特尔发布AI加速器Gaudi3
英特尔发布Gaudi3系列AI加速器,采用先进5nm制程,性能优越,计划于明年推出,与英伟达的H200加速卡竞争。
【AiBase提要】
🚀 性能卓越: 英特尔Gaudi3采用先进5nm制程,带宽提升1.5倍,BF16功率提升4倍,网络算力提升2倍。
💡 市场竞争: Gaudi3计划在2024年占据更大市场份额,与英伟达的H200加速卡直接竞争。
💰 成本优势: 凭借出色性能和竞争力的总体成本,Gaudi3有望在市场上取得更大的成功。
悉尼科技大学成功开发无侵入系统,将脑电波转化为文字
悉尼科技大学的研究团队成功开发了一款便携、无侵入的系统,通过AI模型将脑电波信号转换为文字,为中风或瘫痪患者提供新的交流方式。
【AiBase提要:】
🧠 无需手术或其他侵入性方法,悉尼科技大学研发的系统可解读脑电波并转换为文字。
🤖 应用前景广泛,尤其对于中风或瘫痪患者,为其提供无声思维的沟通方式。
🚀 采用名为DeWave的AI模型,通过佩戴帽子记录脑电活动,实现无侵入、方便日常使用。
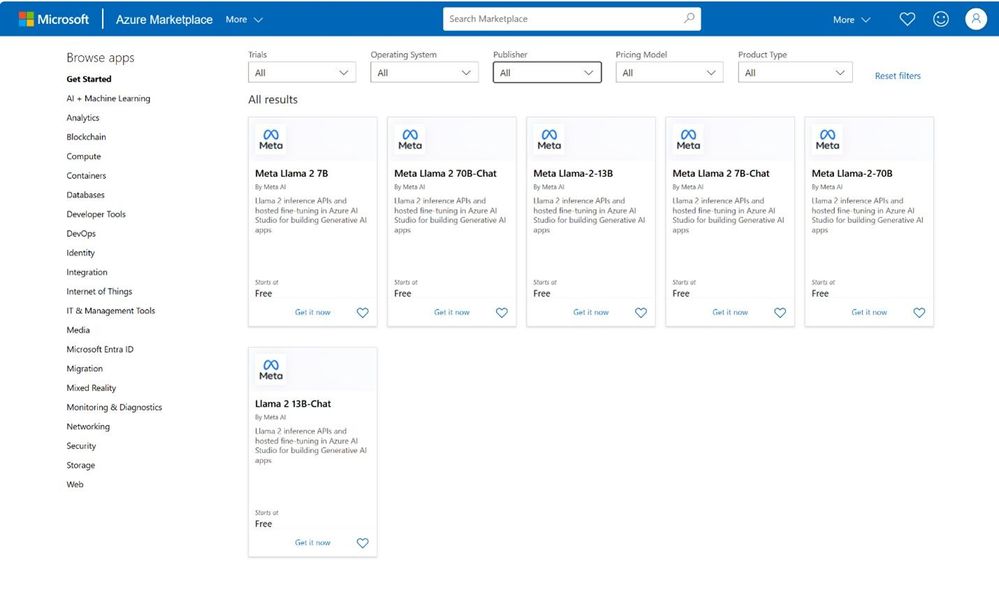
微软扩展Azure AI Studio,引入Llama2和GPT-4Turbo with Vision
微软将Meta竞争对手Llama2引入Azure AI Studio,提供AI模型即服务(MaaS),同时加入OpenAI的GPT-4Turbo with Vision,拓展Azure云平台AI选择。
【AiBase提要:】
🚀 扩展AI服务: 微软整合Meta的Llama2作为模型即服务引入Azure AI Studio,提供多个开源Llama模型,丰富Azure云存储和服务客户的AI选择。
🌐 多样化AI选择: 微软在Azure AI Studio中加入OpenAI的GPT-4Turbo with Vision,为客户提供更多先进的AI工具,包括图像分析和描述能力。
🤖 战略多元化: 微软采取多元化策略,拓展AI模型库,不仅提供与OpenAI合作的模型,还引入竞争对手的开源模型,满足不同客户需求。
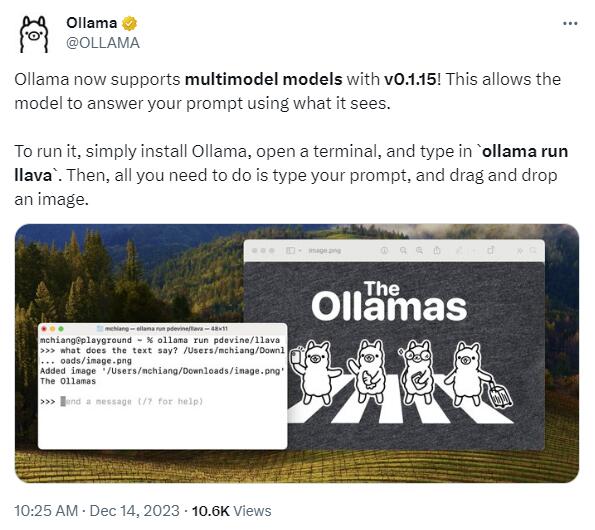
Ollama支持多模态模型使用
Ollama最新版本为macOS和Linux用户提供了多模态模型支持,通过输入命令“ollama run llava”并下载llava-7B模型,用户可轻松在本地运行Llama2、Code Llama等模型,支持近二十多个语言模型系列。
官网地址:https://top.aibase.com/tool/ollama
【AiBase提要:】
🚀 多模态模型支持: Ollama最新版本允许用户在macOS和Linux上本地运行多模态模型,提供更灵活的应用场景。
⚙️ 模型选择与运行: 用户通过输入“ollama run llava”并下载llava-7B模型,即可轻松运行Llama2、Code Llama等模型,拖放图像输入问题。
📈 量化级别与性能权衡: Ollama支持多个语言模型系列和不同的"tags",用户可根据需求选择量化级别,权衡模型精确度和运行速度。
🤖📈💻💡大模型动态
阿里图像生成视频模型I2VGen-XL代码发布
阿里于11月份发布的图像生成视频模型I2VGen-XL,如期开源了其代码和模型,该模型通过3500万个单镜头文本视频对和60亿个文本图像对的数据训练,提高了生成视频的语义准确性和细节连续性。

代码地址:https://github.com/damo-vilab/i2vgen-xl
【AiBase提要:】
👁️🗨️ 基础阶段和优化阶段: I2VGen-XL模型分为基础阶段和优化阶段,通过分层编码器保持语义连贯性,整合简短文本增强视频细节。
📈 模型优化数据: 研究团队通过收集约3500万个单镜头文本视频对和60亿个文本图像对的数据,优化了I2VGen-XL模型,提高了生成视频的语义准确性、细节连续性和清晰度。
🚀 代码开源地址: 阿里图像生成视频模型I2VGen-XL的代码和模型已在GitHub上开源,为研究者和开发者提供了可探索和使用的资源。
元象开源 XVERSE-65B-Chat 大模型
元象宣布开源 XVERSE-65B-Chat 大模型,提供强大且无条件免费商用工具,广大开发者可登录官网或小程序体验。
Github:https://github.com/xverse-ai/XVERSE-65B
【AiBase提要:】
🚀 开源力量: 元象发布 XVERSE-65B-Chat,是国内最早、参数最大的免费商用模型,在SuperCLUE评测中位居国内开源总分第一。
🧠 卓越性能: XVERSE-65B 相较于其他模型,拥有更强的理解、生成、逻辑和记忆能力,能处理更多样、更困难的任务。
🔗 资源链接: 开发者可通过 Github、Hugging Face、ModelScope等平台获取 XVERSE-65B-Chat 模型。
上海交通大学携手百度发布白玉兰科学大模型2.0版
上海交通大学与百度智能云合作发布了包括“法律开源”和“化学合成2.0”在内的“白玉兰科学大模型2.0版”,其中“法律开源”模型在法律领域表现出色,超越了同类中文通用大模型和中文法律大模型。
【AiBase提要:】
🔍 上海交通大学与百度共同发布白玉兰科学大模型2.0版,包含法律和化学领域。
🧠 “白玉兰科学大模型—法律开源”在领域预训练基础上,通过融合法律知识,超越同类模型。
🌐 此次发布标志着双方在AI for Science领域取得新进展,为校企深入合作树立了新典范。
谷歌推生成式AI医疗模型MedLM
谷歌发布MedLM生成式AI医疗模型,基于Med-PaLM2,美国医学执照考试准确率达85%,计划整合Gemini模型服务全球医疗行业。
【AiBase提要】
🚀 谷歌MedLM模型,专为医疗保健行业设计,通过美国医学执照考试取得85%准确率。
🏥 MedLM基于Med-PaLM2,相较首代提高18%,谷歌计划整合Gemini模型拓展其人工智能功能。
🌍 MedLM服务医疗行业各方面,包括医院、药物开发、聊天机器人等,已在多个组织中测试并逐步投入生产。
🤖📱💼AI应用
Spotify测试AI歌单功能
Spotify正在测试基于AI技术和用户提示创建歌单的功能,通过ChatGPT响应用户输入,展示了AI驱动的歌单生成过程。
【AiBase提要:】
🎵 Spotify确认测试基于提示的AI歌单功能,允许用户使用AI技术和提示创建歌单。
🤖 视频显示用户通过“Your Library”选项在Spotify应用中使用ChatGPT创建歌单的过程,AI响应用户的提示并生成歌单。
🌐 Spotify公司确认测试,但未透露技术细节、工作原理,也未承诺正式上线时间。
视频重绘工具DomoAI 不用SD视频一键就能转动漫
DomoAI是一款免费的人工智能艺术生成器,通过简单操作和多样化预设模型,用户能在20秒内将文本转化为高质量艺术品,实现快速创作和保持一致的绘画风格。

官网地址:https://top.aibase.com/tool/domoai
【AiBase提要:】
🎨 创意释放: DomoAI通过简短文本提示,如描述老巫师或水下游泳的女孩,帮助用户快速实现个性化创作。
🌐 社区互动: 提供社区平台,用户可在Discord中获取支持,使DomoAI成为与用户互动发展的艺术创作社区。
🚀 高效创作平台: DomoAI以20秒内将文本转化为艺术品的速度、简单操作和丰富预设模型,为用户提供高效有趣的艺术创作平台。
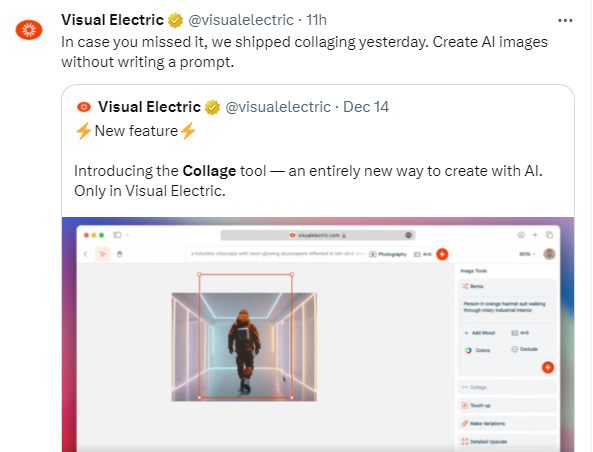
Visual Electric发布多张图像组合重绘功能
AI图像生成工具Visual Electric推出两大功能,使图像创作者能够轻松将多张图像组合重绘,提高创作流程的灵活性。设计师可分开生成各个主体,然后通过重绘功能将它们组合,实现更直观的创意实现。
官网地址:https://top.aibase.com/tool/visual-electric
【AiBase提要:】
👥 多图组合: Visual Electric允许用户将生成的多张图像进行组合,为设计师提供更多灵活性,支持分阶段创作。
🎨 自定义风格: 利用几张图片,用户能够快速自定义图像生成风格,类似于Lora训练的方式,拓展创作可能性。
🚀 直观创意实现: 推出的新功能使图像生成过程更加灵活和直观,让设计师更轻松地实现他们的创意想法,提升创作过程的乐趣。
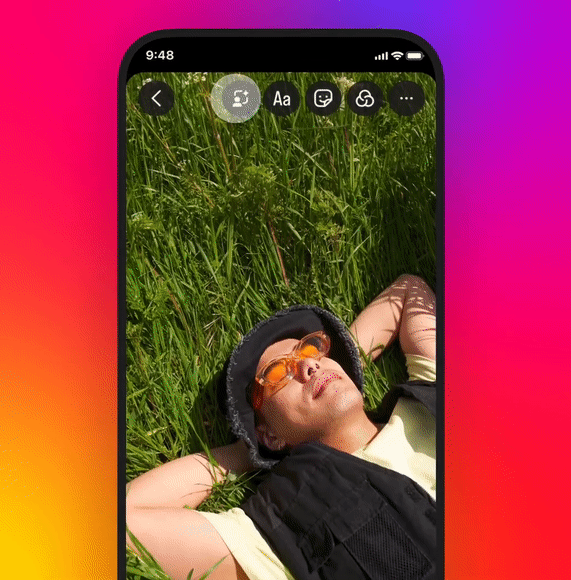
Instagram推出生成式AI背景编辑工具
Instagram推出生成式AI背景编辑工具,让用户通过各种提示定制独特图片背景,促进互动体验。
【AiBase提要:】
🎨 用户可通过提示如“走红地毯”自定义背景。
🤳 发布后,其他用户可参与并互动,轻松分享独特图像故事。
🌐 生成式AI技术逐渐成为社交媒体创意表达和用户互动的关键。
👨💻💡🎯聚焦开发者
谷歌开发实时渲染大型三维场景技术SMERF
Google团队推出的SMERF技术能在最大300平方米的房间内实时创建逼真的三维场景,支持智能手机和笔记本,具备60fps实时渲染和完整的六自由度导航。该技术采用分层模型划分和蒸馏训练策略,解决了渲染大型三维场景性能和质量问题,提供更真实、流畅的三维体验。
项目地址:https://smerf-3d.github.io/
【AiBase提要:】
🌐 实时渲染大型场景: SMERF技术能在300平方米房间内实时渲染逼真三维场景,支持60fps的流畅导航。
🎮 高效内存使用: 采用分层模型和蒸馏训练,提高了处理效率和渲染速度,即使在内存有限设备上也能流畅运行。
📱 普及性和真实感: 通过普通智能手机和笔记本实现,用户可获得接近照片级真实感的自由三维体验。
AI生成前端代码项目“Coffee”
通过人工智能工具“Coffee”,前端开发者能够以零依赖、零设置的方式,实现对React代码库的快速生成、编辑和维护,显著提高开发效率。
代码地址:https://github.com/Coframe/coffee
【AiBase提要:】
🚀 创新工具Coffee: Coffee利用人工智能技术,支持React代码库的快速生成和编辑,无需额外依赖,使前端开发更高效。
🛠️ 统一开发体验: 无论是新建组件还是编辑现有组件,Coffee提供相同的开发体验,生成清晰可维护的代码,符合生产标准。
🌐 未来扩展计划: Coffee计划扩展对其他流行前端框架的支持,包括Vue、Svelte等,以拓宽其适用范围。
谷歌发布NeRFiller,用2D图像补全3D场景
谷歌与加州大学伯克利分校的研究人员合作推出NeRFiller框架,通过2D图像修复缺失的3D场景,采用网格先验和联合多视角补全策略,显著提高修复效果和重建效率。

即将开源地址:https://github.com/ethanweber/nerfiller
论文:https://arxiv.org/abs/2312.04560
【AiBase提要:】
🌐 多视角一致性补全: NeRFiller采用网格先验和联合多视角补全两种策略,通过2x2网格形状提供给补全模型,增加一致性修复效果。
🔍3D场景整合迭代优化: NeRFiller通过迭代方法将2D图像补全结果整合到全局一致的3D场景中,提升3D场景的几何形态和一致性。
🚀 重建效率提升: 经测试数据显示,NeRFiller相比原始数据在PSNR、SSIM等多个评估指标上表现更出色,重建效率提升了约10倍。
- 0000
- 0000
- 0000
- 0000
- 0000



