LLM360: 首个完全开源和透明的大语言模型
**划重点:**
1. 🌐 开源LLMs(如LLaMA、Falcon和Mistral)选择性公开了组件,而LLM360计划通过完全开源训练过程,支持AI研究的透明性和可重复性。
2. 🚀 LLM360发布两个7B参数的LLMs,AMBER和CRYSTALCODER,附带训练代码、数据、中间检查点和分析,旨在推动开源LLMs的全面透明。
3. 📈 研究在四个数据集上展示了AMBER模型在预训练期间的性能,强调对LLMs进行全方位开源,包括释放检查点、数据块和评估结果,以实现全面分析和可重复性。
在众多开源的大型语言模型(LLMs)中,如LLaMA、Falcon和Mistral等,大多数仅公开了特定组件,如最终模型权重或推理脚本。技术文档通常集中在更广泛的设计方面和基本指标上,限制了该领域的进展,因为训练方法的清晰度不足,导致团队不断努力揭示训练过程的众多方面。

为支持开放和协作的AI研究,来自Petuum、MBZUAI、USC、CMU、UIUC和UCSD的研究人员推出了LLM360。这一倡议旨在通过使端到端LLM训练过程对每个人都透明且可重现,全面开源LLMs。LLM360的目标是让所有训练代码和数据、模型检查点以及中间结果都能为社区所用。
与LLM360最接近的项目是Pythia,也旨在实现LLMs的完全可重复性。EleutherAI模型,如GPT-J和GPT-NeoX,已发布了训练代码、数据集和中间模型检查点,展示了开源训练代码的价值。INCITE、MPT和OpenLLaMA发布了训练代码和训练数据集,RedPajama也发布了中间模型检查点。
LLM360发布了两个7B参数的LLMs,分别是AMBER和CRYSTALCODER,连同它们的训练代码、数据、中间检查点和分析。研究回顾了预训练数据集的详细信息,包括数据预处理、格式、数据混合比例以及LLM模型的架构细节。
研究提到了在先前工作中引入的记忆得分,并发布了研究人员易于找到其对应物的度量、数据块和检查点。该研究还强调了消除LLMs预先训练的数据的重要性,以及有关数据过滤、处理和训练顺序的详细信息,以评估LLMs的风险。
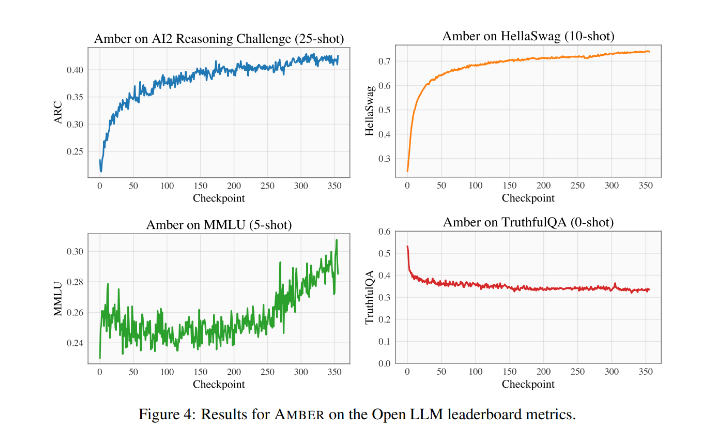
研究在四个数据集(ARC、HellaSwag、MMLU和TruthfulQA)上展示了模型在预训练期间的性能。HellaSwag和ARC的评估分数在预训练期间单调增加,而TruthfulQA的分数下降。MMLU的分数最初下降,然后开始增长。相对于ARC,AMBER的性能在诸如MMLU之类的分数上相对竞争,但在ARC方面稍逊色。微调的AMBER模型在性能上表现强于其他类似模型。
LLM360是一个推动开源LLMs全面透明的倡议。该研究发布了两个7B LLMs,AMBER和CRYSTALCODER,连同它们的训练代码、数据、中间模型检查点和分析。该研究强调了从各个角度开源LLMs的重要性,包括释放检查点、数据块和评估结果,以实现全面分析和可重复性。阅读论文以获取更多信息,对这项研究的所有贡献归功于该项目的研究人员。如果您喜欢他们的工作,不要忘记加入ML SubReddit、Facebook社群、Discord频道和电子邮件通讯,以获取最新的AI研究新闻和有趣的AI项目。
论文网址:https://arxiv.org/abs/2312.06550
项目网址:https://t.co/ZcLPtYQhdQ
- 0000
- 0000
- 0000
- 0000
- 0004