AI视野:Midjourney正式上线Alpha网页版;OpenAI恢复会员注册;腾讯发布视频生成模型AnimateZero;微软发布小语言模型AI Phi-2
🤖📱💼AI应用
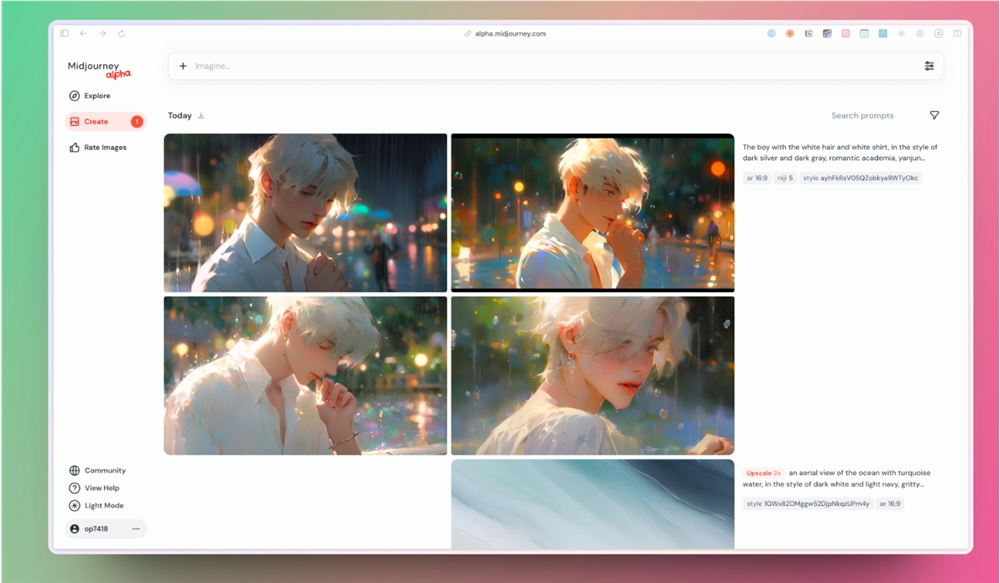
Midjourney正式上线Alpha网页版!支持已生成图片设置参数回填
Midjourney Alpha全新升级,生成用户界面更便捷,成功生成1万张图片即可获得权限,可视化图像参数支持点击回填到提示词输入框,提升生成体验。
截图自归藏
【AiBase提要:】
🌐 生成体验提升: Midjourney Alpha升级界面更便捷,所有参数以可视化图像形式展示,成功生成1万张图片即可获得权限。
🖼️ 可视化回填功能: 已生成的图片参数支持点击回填到提示词输入框,简化分割提示词的操作,提升用户体验。
🔄 图像识别升级: 图像生成功能升级,选择已生成图片时系统显示艺术家和风格的提示词,方便点击选择进行回填,使操作更加简便。
runway支持人物面部生成指定表情
Runway宣布运动笔刷功能升级,结合提示词实现对人物面部表情的精准控制,让制作人员更方便地在创作过程中控制人物的表情。

【AiBase提要:】
🎨 运动笔刷升级: Runway运动笔刷功能升级,通过结合提示词,能够在人物面部快速准确地产生指定表情,提高创作效率。
🚀 创新技术应用: 运动笔刷是Runway推出的一项创新技术,用户无需输入文字,通过手势操作即可使图片动起来,简化视频制作流程。
🌟 生动人物形象: 制作人员可以更方便地控制人物表情,使人物形象更加生动,为内容创作提供了更灵活的可能性。
Snapchat推出AI生成照片功能
Snapchat Plus会员现在可通过AI生成图像,选择文本提示或预制选项,丰富定制照片,包括背景填充和主题变换。
【AiBase提要:】
🤖 Snapchat Plus会员通过点击“AI”按钮,利用AI生成图像功能,根据文本提示创建并发送图像。
🌌 新功能包括AI填充背景,使主体看起来离相机更远,以及通过“Dreams”功能为照片添加主题变换。
📷 Snapchat Plus会员每月可免费获得一个包含八个“Dreams”的礼包,丰富用户定制和分享体验。
🤖📈💻💡大模型动态
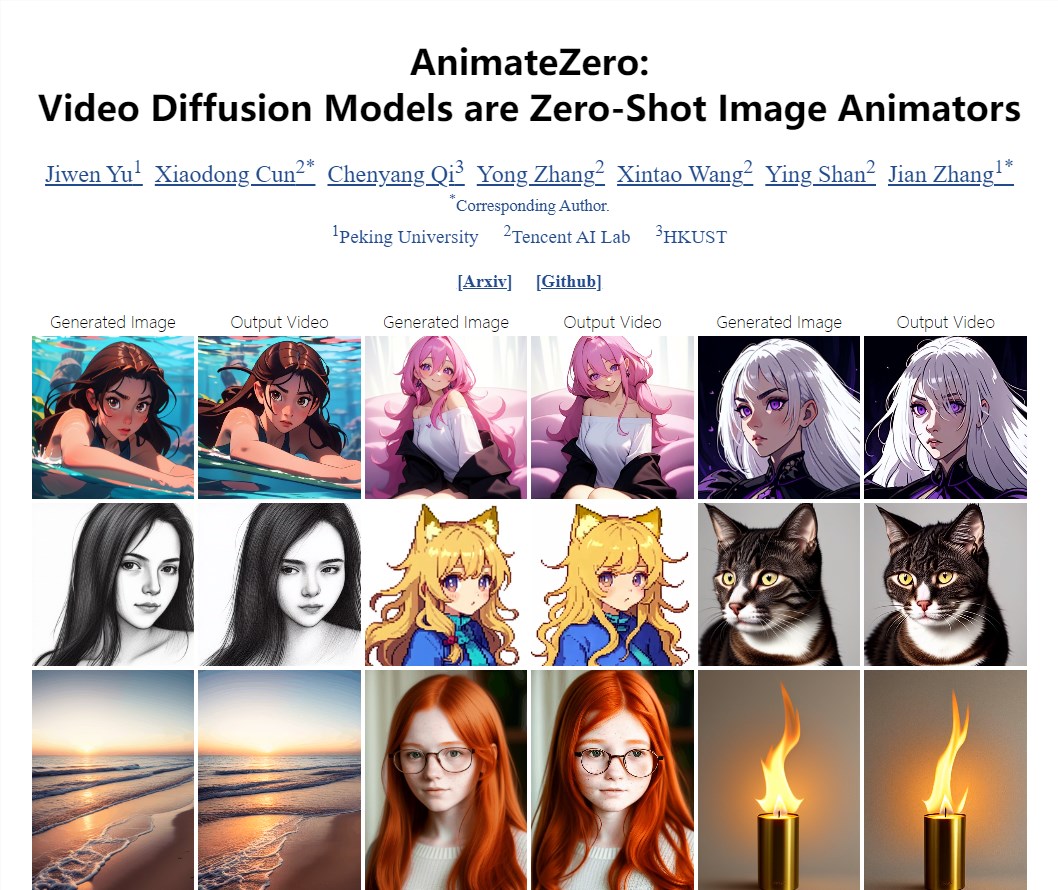
腾讯发布视频生成模型AnimateZero 效果秒杀Animatediff
腾讯最新发布的AnimateZero视频生成模型效果优于Animatediff,具备更好的SD生态兼容性,并采用社区SD模型进行演示。
项目地址:https://vvictoryuki.github.io/animatezero.github.io/
【AiBase提要:】
🚀 AnimateZero效果超群,优于Animatediff,更兼容SD生态。
💡 采用视频扩散模型,解决传统模型不透明、难以控制等问题。
🌐 在应用方面展示多种场景,提供高质量视频编辑辅助工具。
微软发布小语言模型AI Phi-2
微软研究院推出Phi-2小语言模型,参数达27亿,性能媲美Meta的Llama2-7B和Mistral-7B。尽管规模仅为Llama2-7B的一半,Phi-2性能更佳,且在回答物理问题和指导学生方面表现出色。然而,目前仅限用于研究目的,不可用于商业用途。
【AiBase提要】
💡 微软发布27亿参数的小语言模型Phi-2,性能与更大的Llama2-7B和Mistral-7B相当。
💪 Phi-2在回答物理问题和学生指导方面展现出更好的性能,毒性和偏差比Llama2更少。
🚫 Phi-2目前仅限用于研究目的,商业用途受限。
阿里、港大推动态视频生成模型LivePhoto
阿里巴巴、香港大学、蚂蚁集团联合推出LivePhoto,这是一种创新的动态视频生成模型,通过图像内容控制、运动建模、额外控制指令等模块,精准生成高质量动态视频。
论文地址:https://arxiv.org/abs/2312.02928
【AiBase提要:】
🌟 创新模型: 阿里、港大、蚂蚁集团合作推出LivePhoto,基于Stable Diffusion的动态视频生成模型,结合图像内容控制、运动建模、额外控制指令。
🔄 卓越性能: LivePhoto在多轮测试中展现出卓越性能,与主流模型如Gen-2、Pikalabs相比效果显著,用户可通过调节运动强度定制视频中的运动方式。
📄 零样本生成: LivePhoto在零样本视频动画生成性能方面表现出色,用户通过简单调节运动强度能自由定制视频中的运动方式。
通义千问72B模型荣登大模型评测平台OpenCompass榜首
通义千问72B模型以67.1的高分在中国权威模型评估平台OpenCompass上获得榜首,显示出其在学科、语言、知识、理解和推理等五个维度的全面能力。
【AiBase提要】
🏆 通义千问72B模型以67.1高分登顶OpenCompass模型评测平台,展现在多维度全面评估中的卓越表现。
🚀 阿里云开源的Qwen-72B模型在十个权威基准测评中超越开源和商业模型,成为业界最强大的开源大型模型。
🌐 通义千问-72B在中文数据集评测中显著优于其他模型,处理最长为32k的文本输入,性能超越ChatGPT-3.5-16k。
📰🤖📢AI新鲜事
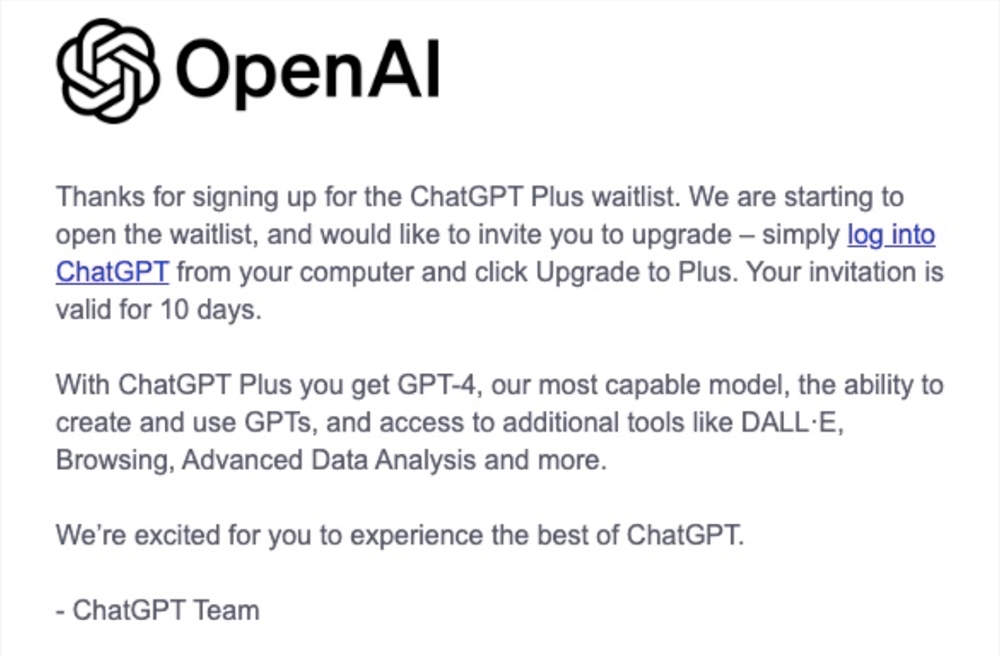
OpenAI恢复会员注册
OpenAI开始逐步恢复ChatGPT Plus注册,已向部分用户发出邀请,并表示感谢用户注册候补名单。
【AiBase提要:】
🔄 逐步恢复注册: OpenAI开始逐渐允许ChatGPT Plus注册,已向部分用户发出邀请,解决先前因使用量激增而暂停注册的问题。
🙌 邀请函内容: 用户收到邀请函,感谢注册候补名单,有效期10天,可通过电脑登录ChatGPT升级到Plus,享受GPT-4和其他工具。
💻 用户反应: 先前的“ChatGPT Plus绝版”消息引起一些用户在eBay上租售账户或高价出售邀请码,突显对ChatGPT Plus的高度关注。
Meta使用盗版书籍训练AI模型遭指控
Meta公司在夏季提起的版权侵权诉讼中,被指控无视律师的警告,使用数千本盗版书籍训练其AI模型。最新提交文件揭示了Meta关联研究员在Discord上讨论数据集采购的聊天记录,显示公司或许明知使用这些书籍存在法律风险。
【AiBase提要:】
🚨 法律风险忽视: Meta被控无视律师警告,使用受版权保护的书籍进行AI模型训练。
📄 聊天记录揭示: 提交的新文件包括研究员在Discord上的聊天记录,或许表明Meta知晓其行为可能涉及法律问题。
💼 诉讼背景: 一些著名作者起诉Meta未经许可使用其作品训练人工智能语言模型Llama,公司尚未对指控回应。
OpenAI非营利部门去年净收入不足4.5万美元
OpenAI的非营利部门在最新税务文件中披露,去年净收入仅为44,485美元,尽管其盈利业务可能为公司创造了数百万美元的收入,引起外界关注。
【AiBase提要:】
📉 OpenAI非营利部门去年净收入仅为44,485美元,与其盈利业务(如ChatGPT)创造的数百万美元收入形成鲜明对比。
💰 OpenAI的盈利部门可能估值高达900亿美元,微软投资100亿美元持有其49%股份,引发了对公司结构的关注。
🧐 OpenAI的企业结构受到争议,接受私人投资数十亿美元,与其他非营利组织不同,引发了透明度和公共信任的讨论。
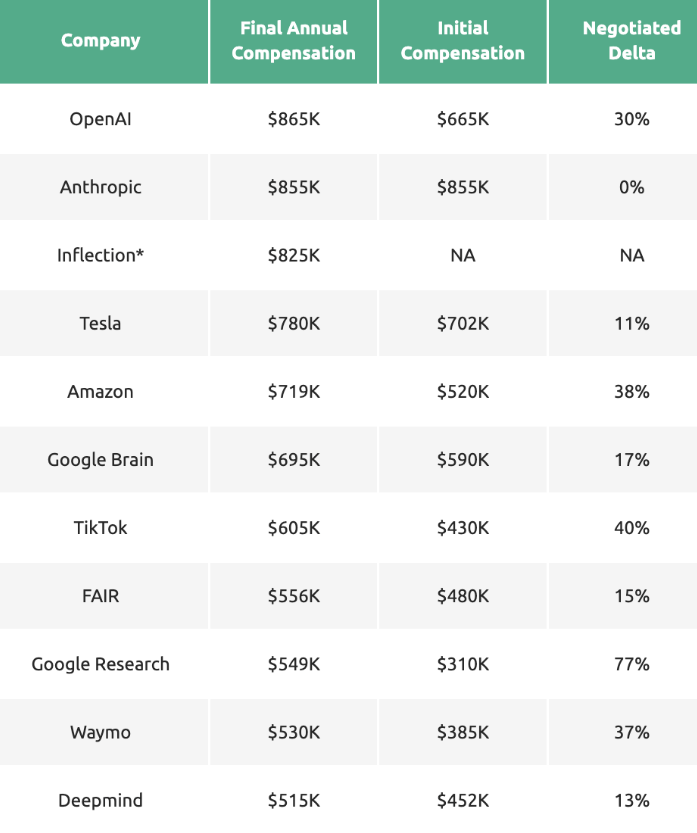
顶尖AI公司薪酬榜曝光:600万天价年薪震惊网友
一张最新薪酬表格曝光,显示OpenAI领衔全美AI公司,提供高达600万美元年薪,引发社会广泛热议。初级码农时薪低至85美元,突显AI行业薪资差距。网友对高薪AI科学家和低薪工程师的差异表示质疑。各大科技公司年薪不一,但大多数超过百万美元。未来AI领域人才需求增长,薪资引起广泛关注。
【AiBase提要:】
🌐 OpenAI以600万美元年薪领衔AI公司榜单。
💰 薪资差距悬殊,初级码农时薪仅为85美元。
🚀 AI领域需求升高,未来薪酬或将持续吸引关注。
特斯拉人形机器人Optimus二代上线
特斯拉人形机器人Optimus二代上线,展示更灵活的双手和轻盈身体,具备对物体分类和瑜伽动作等新能力,引领机器人技术创新。
【AiBase提要:】
🌟 特斯拉人形机器人Optimus二代亮相,经过两年半的练习,展示出更灵活的双手和轻盈的身体。
🤖 Optimus Gen2配备全新手,拥有11个自由度,能灵巧处理精细物体,展示触觉处理能力。
🚀 特斯拉人形机器人展示惊人的进步速度,包括对物体分类和瑜伽动作等新能力。
Meta 推出雷朋智能眼镜的多模态 AI 功能测试
Meta宣布早期访问测试其多模态AI功能,应用于Ray-Ban智能眼镜,通过摄像头和麦克风告知用户周围视听信息,包括物体识别和语言翻译。
【AiBase提要】
👓 智能眼镜新体验: Meta推出早期测试,让Ray-Ban智能眼镜具备多模态AI功能,用户通过眼镜体验物体识别和语言翻译。
🔍 全天候互动: 用户可通过眼镜与Meta AI助手全天对话,提问并得到智能建议,开创全新智能眼镜应用场景。
🌍 测试范围有限: 初期测试仅限于美国,选择加入的少数人参与,拓展智能眼镜在用户生活中的潜在应用。
👨💻💡🎯聚焦开发者
南大提出全新框架VividTalk 一张照片一段声音秒生超逼真视频
南大等机构研究人员推出VividTalk框架,通过一段音频和一张照片生成高质量、富有表现力的说话视频,实现口型和音频的无缝对齐。

论文地址:https://arxiv.org/pdf/2312.01841.pdf
【AiBase提要:】
🌐 全新框架VividTalk: 南大研究人员提出通用框架,通过音频和照片生成逼真说话视频。
🎙️ 两阶段生成方法: 采用多分支Transformer网络建模音频上下文和渲染投影纹理,实现全面建模运动。
🌐 优越生成质量: VividTalk展现出在多语言支持下生成具有丰富表情和自然头部姿势的口型同步视频的优越性能。
趣味项目CLoT:训练LLM更幽默地回答问题
趣味项目CLoT通过日本传统喜剧游戏“大喜利”挑战AI,培养其成为幽默吐槽高手。研究人员构建了多模态Oogiri-GO数据集,通过特殊训练方法使AI学会在游戏中产生创意和幽默回答。CLoT显著提高了大语言模型(LLM)在多种Oogiri游戏中的幽默表现,展现了卓越的创造性和泛化能力。
【AiBase提要:】
🤖 CLoT项目通过"大喜利"游戏挑战AI,培养其成为幽默吐槽高手。
🎭 构建多模态Oogiri-GO数据集,训练AI在游戏中生成创意和幽默回答。
🚀 CLoT显著提高LLM在Oogiri游戏中的幽默表现,展现出卓越的创造性和泛化能力。
HiFi4G渲染技术实现25倍压缩率,照片级真实人体建模和高效渲染
上海科技大学、NeuDim、字节跳动和DGene的研究团队联合发布的HiFi4G渲染技术,以紧凑的高斯喷溅表示法和双图机制为基础,实现了25倍压缩率。
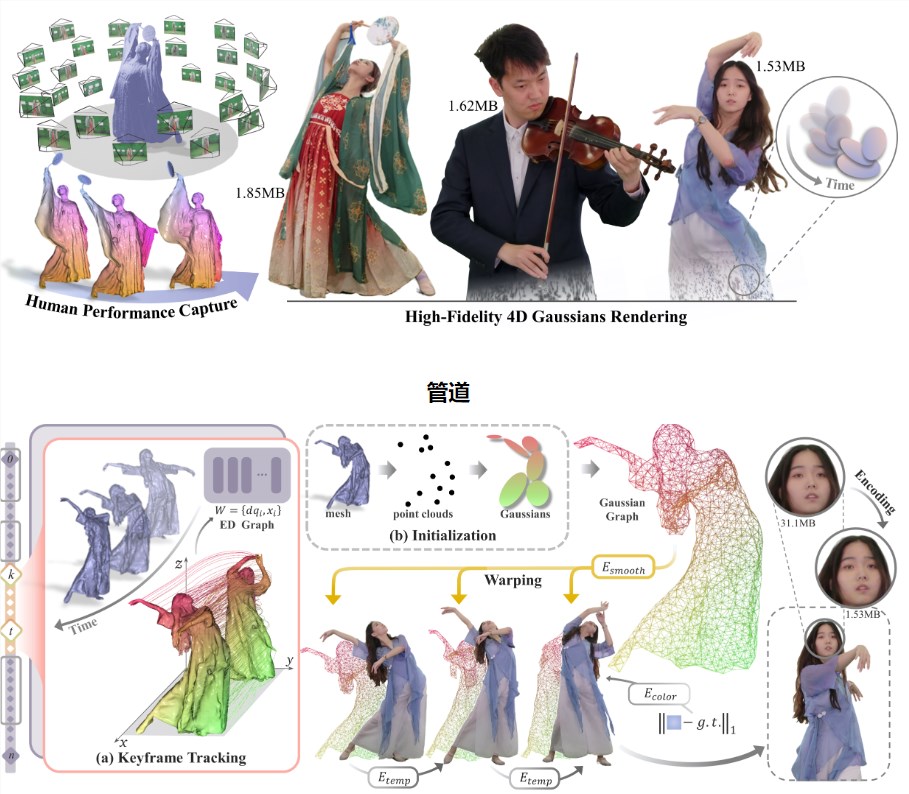
项目网址:https://nowheretrix.github.io/HiFi4G/
论文网址:https://arxiv.org/abs/2312.03461
【AiBase提要】
1. 🌐 HiFi4G实现了从密集视频中重新创建高保真4D人体表演的全显式和紧凑方法。
2. 🎮 HiFi4G在优化速度、渲染质量和存储开销方面明显优于当前的隐式渲染技术。
3. 📦 研究团队提供了一种压缩方法,使HiFi4G在每帧不到2MB的存储空间下,以约25倍的压缩率,可在各种设备上实现沉浸式观看人体表演。
- 0001
- 0000
- 0000
- 0000
 0000
0000



