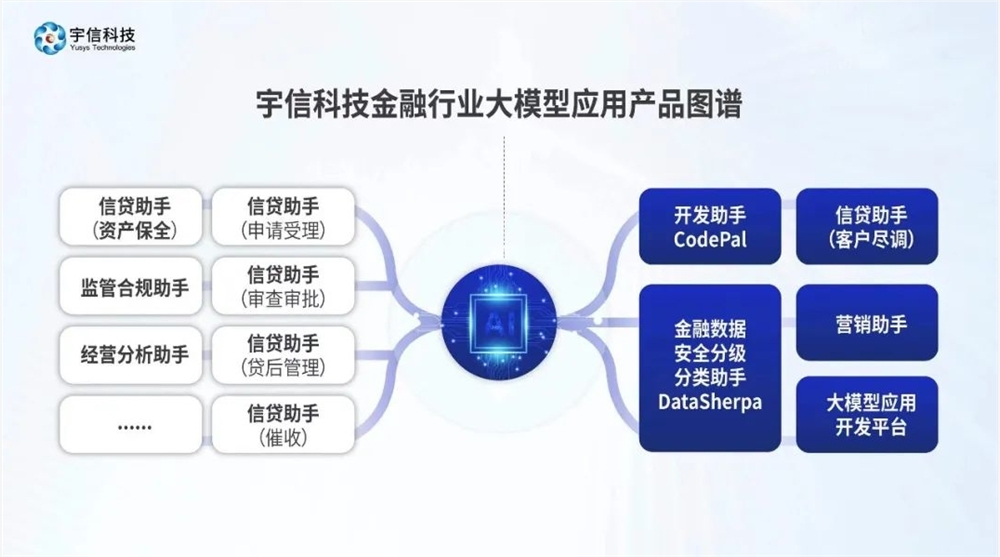
智谱AI发布评分模型CritiqueLLM 可评估文本生成模型性能
站长网2023-12-12 14:41:501阅
近日,智谱AI发布了高质量、低成本的评分模型CritiqueLLM,用于评估文本生成模型的性能。
传统的评价指标如 BLEU 和 ROUGE 主要基于 n-gram 重合度来计算评分,缺乏对整体语义的把握。而基于模型的评价方法则对基座模型的选取非常依赖,只有顶级的大模型才能取得令人满意的效果。
为了解决这些问题,CritiqueLLM 提出了一种可解释、可扩展的文本质量评价模型。它能够针对各种任务生成高质量的评分和评价解释。在含参考文本的场景下,CritiqueLLM 将大模型生成文本和参考文本进行对比,并给出了评分。
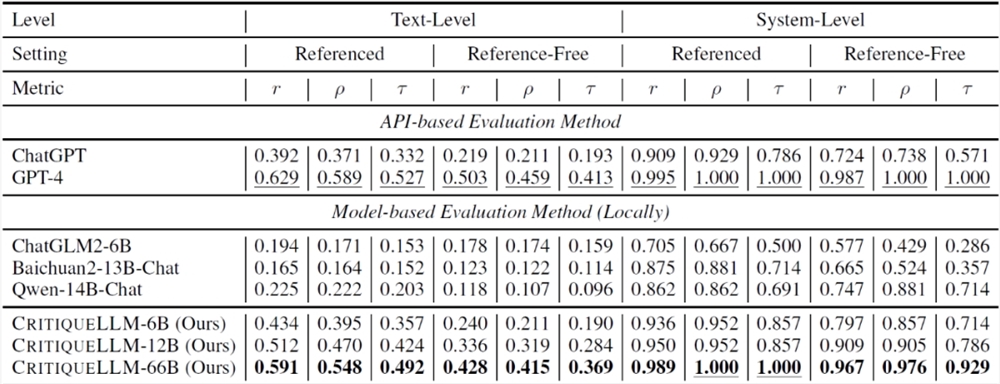
在8类常见的任务中,CritiqueLLM 的评价分数与人工评分的相关系数显著超过了其他模型,尤其是在无参考文本设定下,CritiqueLLM 在3个任务上超过了 GPT-4,达到了最优的评价性能。
CritiqueLLM 的方法包括四个主要步骤:用户询问增广、含参考文本评价数据收集、无参考文本评价数据改写和训练 CritiqueLLM 模型。通过这些步骤,可以得到适用于含参考文本和无参考文本设定的两种 CritiqueLLM 模型,用于评估文本生成模型的性能。
论文链接:https://arxiv.org/abs/2311.18702
Github 链接:https://github.com/thu-coai/CritiqueLLM
0001
评论列表
共(0)条相关推荐
- 0000
- 0000


 0001
0001

 0001
0001
 0000
0000