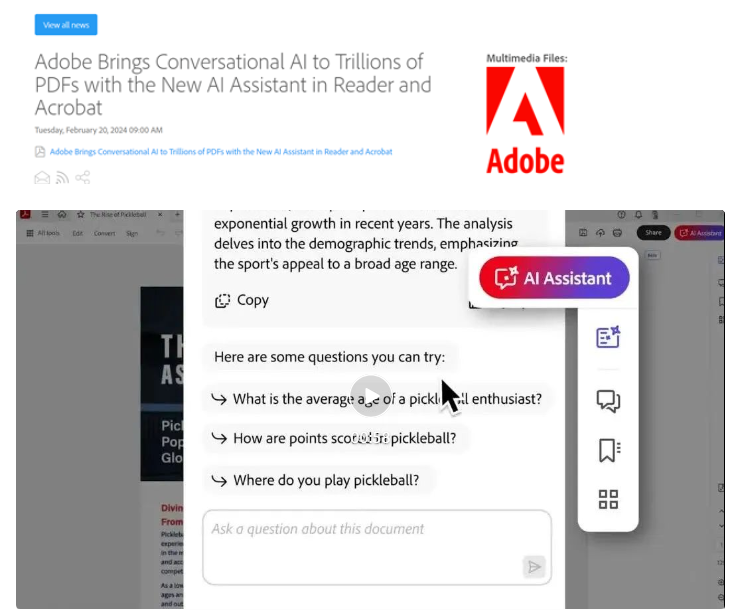
谷歌祭出多模态“杀器” Gemini真能碾压GPT-4吗?
“最大”、最有能力”、“最佳”、“最高效”,谷歌为其12月7日新发布的多模态大模型Gemini冠上了好几个“最”,与OpenAI GPT-4“比高高”的胜负欲呼之欲出。
区分为Ultra、Pro、Nano三个尺寸的Gemini,不仅号称在各种“AI考试”中得了“高分”,演示视频里显示的Gemini简直就是“听说读写”样样拿的“超级工具”。
按照官方说法,Gemini Ultra最为强大,兼具多模态能力、专业性与准确度,能以图文、语音的形式输入输出不说,具体还能批改数学作业,指导运动员的动作与发力,还能够执行复杂的绘制图表、编码等任务,在MMLU(大规模多任务语言理解)测试里甚至“超越了人类专家”。
不过,目前能供C端普通用户体验的是Gemini Pro版,按官方定位是“在各种任务上扩展的最佳模型”,已集成至谷歌此前发布的对话机器人Bard中;“在设备上执行任务的最高效模型”Gemini Nano将置入谷歌智能手机Pixel8Pro;而“最大且最有能力,适用于高度复杂任务”的Gemini Ultra,谷歌的计划是在明年年初开放给开发者和企业用户。
那么,Gemini真的比GPT-4强吗?
有网友发现,谷歌给出的Gemini Ultra“考试成绩”用的是自家的“试卷”(测试方法);而彭博社指出,Gemini的演示视频非实时,网友们也觉得该视频有剪辑痕迹。
《元宇宙日爆》实测了Bard的数学能力,该对话机器人已植入了精调的Gemini Pro模型,结果显示,Bard对复杂的数学题仍有理解错误,尤其是识图方面。
谷歌展示Gemini“听说读写”能力
Gemini是谷歌从头构建的多模态人工智能大模型。尽管在时间上落后GPT-4许多,但被谷歌以“能力最强”对外推出,“强”的一面是Gemini的多模态能力。
它能够同时处理和解析文本、图像、音频、视频以及代码等多种数据类型,也就是说,用户可以将各种形式的信息输入给Gemini,它不仅能理解,还能分析甚至按你的需求处理任务。
目前,Gemini还在1.0版,按规模不同分为Ultra、Pro和Nano。Ultra版本是适用于高度复杂的任务,而Pro版本则专注于多任务处理,Nano版本则针对移动设备上的应用。三种版本有针对性地适用于多个不同场景,且在多项基准测试中展现出超群实力。
谷歌官方放出的宣传视频展示了Gemini超强的多模态能力,相信看完后你会惊呼。
“超级模型”Gemini Ultra的背后有谷歌发布的测试数据支撑。在32个广泛用于测评大型语言模型(LLM)的学术基准中,它在30个上性能超过了大模型领域当前的技术水平。
Gemini Ultra号称以90.0%的得分成为第一个在MMLU(大规模多任务语言理解)上“胜过人类专家的模型”,该测试使用数学、物理、历史、法律、医学和伦理学等57个学科的组合来测试世界知识和解决问题的能力。Gemini在包括文本和编码在内的一系列基准测试中超越了目前的技术水平。
MMLU是一种针对大模型的语言理解能力的测评,包含了57个关于人类知识的多选题回答任务,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平的人类知识,是目前主流的的大模型语义理解测评之一。
从谷歌给出的测试结果来看,Gemini在理解复杂数据和执行高级任务方面将对GPT-4构成强有力的竞争。
谷歌称Gemini在MMLU测评中首次超越人类专家
由于从一开始构建就基于多模态训练,Gemini Ultra理论上对文字、图片、语音、视频、代码等各种形态的信息都能理解,这就给AI应用和使用场景带来了更多可能性。
例如在教育领域,借助Gemini Ultra的多模态推理技能,凌乱的手写笔记能被理解,学生解题时出错的步骤能被发现,然后给出题目的正确解答和过程。这一套下来,不能说要淘汰教师吧,至少老师们也得到了一个高能AI助手。
Gemini可以批改学生作业
在视频的理解与推理上,Gemini Ultra甚至展现出“足球教练”的素养,能分析运动员的动作与发力,还会给出具体的改进建议。
Gemini可理解视频内容并给运动员提供指导建议
对于复杂的图像理解、代码生成、指令跟踪,Gemini Ultra也不在话下。输入图像与提示次“我希望你采用左上角子图中描绘的函数,将其乘以1000,然后将其添加到左下子图中描绘的函数中,生成matplotlib代码单个结果图”后,Gemini Ultra能够完美的执行逆图形任务来推断生成绘图的代码、执行额外的数学转换并生成相关代码。
从谷歌给出的这些案例看,GeminiUltra简直是“地表最强”的大模型,观众朋友们最想知道的是,这个大模型界的“超级赛亚人”,咱啥时候能用上?
按照谷歌的披露,从12月6号开始,Bard就会上载Gemini Pro的精细调整版本,用于更高级的推理、规划、理解等,这是Bard自推出以来的最大升级。
需要注意的是,集成了Gemini Pro的Bard只提供英语支持,可在全球170多个国家和地区使用,计划在不久的将来扩展到不同的模态,支持新的语言和地区。也就是说,中文用户目前还无法完美体验Gemini Pro。
Gemini Nano最先在谷歌的Pixel8Pro智能手机上应用,从WhatsApp开始,明年将支持更多的消息应用。
在未来几个月中,Gemini还将在更多的产品和服务中推出,包括Search、Ads、Chrome和Duet AI。也就是说,谷歌的搜索引擎中也将输入Gemini能力。
至于“最强”的GeminiUltra,普通用户还得等等。谷歌说,它正在进行信任和安全性检查,在推出前还得通过对人类反馈的微调和强化学习(RLHF)的进一步改进。
在这个过程中,GeminiUltra会有选择地给客户、开发人员、合作伙伴以及安全和责任专家拿来早期实验,等待反馈,然后在明年初向开发人员和企业客户开放。
Ultra的MMLU“试卷”疑为谷歌版
展示的是最强的GeminiUltra,但推出和使用要缓一缓,谷歌这样的操作很快就惹来了怀疑,真比GPT-4强吗?
彭博社就出来“打脸”说,谷歌的模型和OpenAI相比还仍有差距,现在这能力也仅凭演示,而视频演示还是录制的,又不实时,很可能是“精心调整的文本提示与静态图像”。彭博社还指出,Gemini的回答需要其他信息的辅助,在真正的交互中需要暗示性很强的提示。
围观演示视频的网友们也觉得,视频中有很明显的剪辑痕迹,“强大的能力存在水分”。
而谷歌给Gemini Ultra考试的MMLU测评,被网友指出用的是自家出的“试卷”。在57个科目的多选题测试中,得了90分的Ultra,底下分明标着“CoT@32*”,这是谷歌自己调试的测评方案。如果采用和GPT-4同样的标准,它的得分只有83.7,还不如得分86.4的GPT-4。
Gemini Ultra在谷歌调整的测试方案中得分90
学术上的事情太专业,好在谷歌已经把Gemini植入了Bard,尽管用的是Utral的低配版Pro,但也号称能多任务处理,这是普通大众最能直接测试Gemini的方式了。
《元宇宙日爆》直接选用了数学题,因为ChatGPT对数学就不太精通,而有唯一正确性的数学被OpenAI视作通往AGI的基础,咱来看看被输入Gemini能力的Bard是否擅长数学。
我们统一用英文进行提问,题1为求算圆锥体积,题2为稍难的几何证明题。
测试结果表明,Gemini Pro能够准确识别图像以及图片内的文字,也能够正确解决简单数学问题,但在处理复杂数学题时,仍然存在明显错误。题2中的错误就很明显,Bard在第2步将EG与AB两条线错误地证明为相互垂直。
有Gemin Pro能力的Bard做数学题还不完美
这难道是因为Bard用的是Gemini Pro而显得不够强大?那咱只能等Ultra加入再测试了。
而会引入智能手机Pixel8Pro的Gemini Nano,将应用在“记录器摘要”和“Gboard智能回复”两项功能中。
按谷歌说法,即使手机不连网,记录器也可以获得手机对话录音、采访、演示等内容的摘要;而智能回复功能类似挂断电话后的自动回复,Gemini Nano可以识别来信的内容,生成对应的回复。不过,这两项功能,目前也只支持英文文本的识别。
按照DeepMind曾提出的AGI评估框架,在AGI-1阶段,人工智能将能够跨领域和跨模态地进行学习和推理,在多个领域和任务上表现出智能,如问答、摘要、翻译、对话等,实现与人类和其他AI进行基本的沟通和协作,感知和表达简单的情感和价值。
综合Google官方发布与实际测试体验来看,值得期待并有希望超越GPT-4模型的仍是尚未公开发布的Ultra版本,如果这个版本的多模态能力真能如演示般表现,那么谷歌距离它定义的AGI也就不远了。
- 0000
- 0000
- 0000
- 0000
 0000
0000