ChatGPT模型在神经学考试中表现出色,超越人类学生水平
### 划重点:
1. 🤖 ChatGPT大语言模型在神经学考试中表现出色,其中一款模型达到85%的准确率,超过人类神经学生平均水平。
2. 📚 通过评估两个ChatGPT大语言模型(LLMs)在美国精神病学和神经病学委员会题库的问题上的表现,研究人员发现,其中一个模型在考试中显著优于人类平均分(85%对73.8%),成功通过通常难以通过的入学考试。
3. 🏥 近期计算能力的提升和“更智能”人工智能模型的发展使得这些深度学习算法在临床神经学中得到广泛应用,从神经学诊断到治疗和预后等方面都有潜力。
近期发表在JAMA Network Open期刊的一项研究中,研究人员评估了两个ChatGPT大型语言模型(LLMs)在回答美国精神病学和神经学委员会问题库的问题时的表现。他们比较了这两个模型在低阶和高阶问题上的结果与人类神经学生的表现。研究发现,其中一个模型在问题纸上显著优于人类平均分数(85%对73.8%),从而通过了通常难以通过的入学考试。这些发现突显了LLMs的最新进展,并展示了它们如何在进行轻微调整后,成为临床神经学应用的关键资源。
图源备注:图片由AI生成,图片授权服务商Midjourney
随着计算能力的提升和"更智能"的AI模型的发展,机器学习(ML)和其他人工智能(AI)算法越来越多地被应用于以前仅限于人类的领域,包括医学、军 事、教育和科学研究。最近,基于变压器的AI架构——在45TB或更多数据集上训练的AI算法——正在辅助甚至取代传统上由人类执行的角色,包括神经学。庞大的训练数据量,加上不断改进的代码,使这些模型能够呈现逻辑和准确的响应、建议和预测。ChatGPT平台上基于的两个主要算法目前已经开发——LLM1(ChatGPT版本3.5)和LLM2(ChatGPT4)。前者在计算上要求较低,数据处理速度更快,而后者在语境上更准确。
尽管非正式的证据有利于这些模型的实用性,但它们的性能和准确性在科学环境中很少得到测试。有限的现有证据来自对LLM1在美国医学许可考试(USMLE)和眼科学考试中表现的研究,而LLM2版本迄今尚未经过验证。
研究细节:
在这项研究中,研究人员旨在比较LLM1和2在类似委员会书面考试中与人类神经学生的表现。这项横断面研究符合流行病学观察研究加强(STROBE)指南,并将神经学委员会考试作为LLM1和2在高度技术性的人类医学考试中的表现的代理。研究使用了来自美国精神病学和神经学委员会(ABPN)问题库的问题。该库包含2,036个问题,其中80个由于基于视频或图像而被排除。LLM1和LLM2分别来自服务器包含的在线源(ChatGPT3.5和4),并在2021年9月之前进行了训练。人类比较使用了以前版本的ABPN委员会入学考试的实际数据。
测试过程:
在评估过程中,预训练模型LLM1和2无法访问在线资源来验证或改进它们的答案。在模型测试之前,没有进行神经学特定的模型调整或微调。测试过程包括将模型提交给1,956个多项选择题,每个问题有一个正确答案,三到五个干扰项。根据学习和评估的布鲁姆分类法,所有问题被分类为低阶(基本理解和记忆)和高阶(应用、分析或评估思考为基础)的问题。
性能评估:
评估标准将70%或更高的得分视为考试的最低及格分数。通过50个独立查询测试模型的答案可再现性,这些查询旨在探究自洽性原则。
统计分析:
统计分析包括对模型性能和先前人类结果之间的单变量、顺序特定比较,使用卡方(χ2)检验(对于26个确定的问题子组进行Bonferroni校正)。
研究结果:
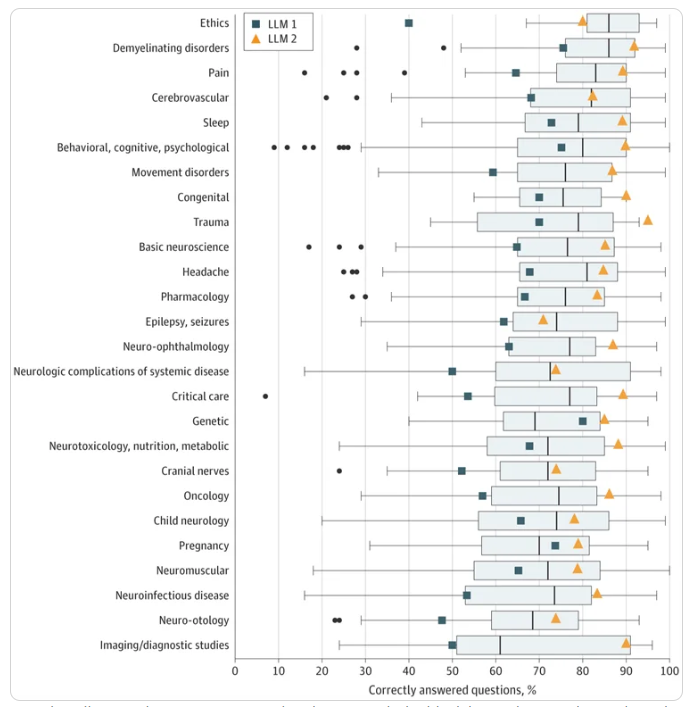
LLM2在所有测试组中表现最佳,获得了85.0%的分数(1956个问题中1662个回答正确)。相比之下,LLM1的分数为66.8%,人类平均为73.8%。模型在低阶问题中的表现最高(分别为1和2的模型分别为71.6%和88.5%)。
在这项研究中,研究人员评估了两个ChatGPT LLMs在神经学委员会考试中的表现。他们发现后期模型在低阶和高阶问题上显著优于前期模型和人类神经学生。尽管在记忆类问题方面表现更强大,但这些结果突显了这些模型在辅助甚至替代人类医学专家在非关键任务中的潜力。
值得注意的是,这些模型没有针对神经学目的进行调整,也没有允许它们访问不断更新的在线资源,这两者都可能进一步提高它们与人类创作者之间的性能差距。
- 0000
- 0000
- 0000
 0000
0000- 0000