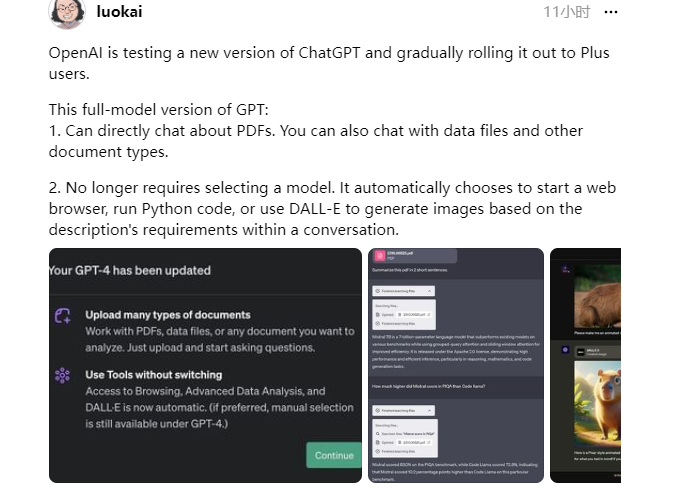
MIT斯坦福Transformer最新研究:过度训练会让中度模型“结构顿悟”
要点:
经过过度训练,中度模型如Transformer表现出结构性泛化能力,被称为"结构顿悟"(Structural Grokking)。
研究发现,对于Transformer类模型,长时间训练后,模型在泛化到新结构输入时能够有效地捕捉到句子的层级结构。
结果显示,模型的深度对结构顿悟呈倒U形缩放,中深度模型的泛化能力较深度和浅度模型更强。
最新研究指出,经过过度训练,中度的Transformer模型能够展现出结构性泛化能力,这一现象被称为"结构顿悟"。在自然语言处理中,先前的研究认为像Transformer这样的神经序列模型在泛化到新的结构输入时难以有效地捕捉句子的层级结构。

论文地址:https://arxiv.org/pdf/2305.18741.pdf
然而,斯坦福和MIT的研究人员发现,通过对Transformer类模型进行长时间的训练,模型能够获得这种结构性的泛化能力。他们将这一现象命名为"结构顿悟",形容为神经网络经历了一个"aha moment",在训练的某一刻忽然实现了对层级结构的理解。这种现象的发生被证明在不同数据集上呈现出倒U形的深度缩放,中深度模型的泛化能力表现最佳。
研究进一步指出,提前停止训练会导致泛化性能被低估,而中度深度的Transformer模型在泛化到新结构输入时呈现出显著的优势。研究还分析了结构顿悟的内部属性,包括参数权重的L2norm、注意力稀疏性和模型的树结构性。结果显示,中度深度模型在这些属性上表现出最佳的结构顿悟,而权重范数和注意力稀疏性的动态变化与模型的泛化性能密切相关。
这项研究为理解神经序列模型的泛化机制提供了新的视角。通过揭示结构顿悟的存在,研究强调了模型深度与泛化性能之间的关系,并为改善自然语言处理模型的泛化能力提供了有价值的启示。这一发现有望在未来的深度学习研究中引起更多关注,为模型设计和训练策略提供指导。
- 0003
- 0000
 0000
0000- 0001
- 0000