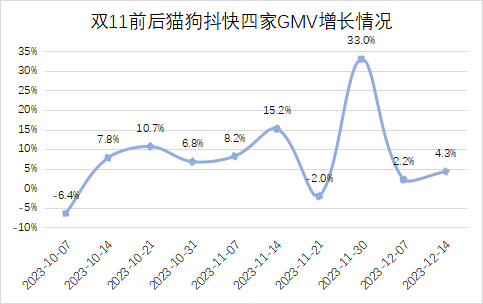
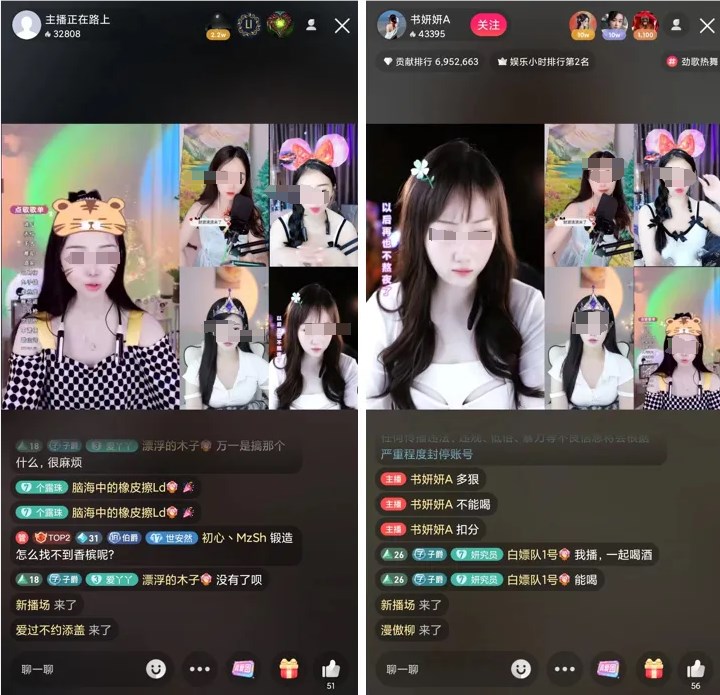
新视频编辑模型VideoSwap 可精细化替换视频主体
**划重点:**
🔄 视频主体定制替换: VideoSwap框架通过语义点对应实现源视频主体与目标主体的形状变化替换。
🚗 形状变化挑战: 传统基于扩散的视频编辑在处理形状变化时效果有限,VideoSwap引入语义点对应以应对这一挑战。
🌐 视频编辑革新: 采用语义点对应的VideoSwap框架在自定义视频主体替换方面取得了卓越的效果,为视频编辑领域带来创新。
最近,视频编辑领域迎来了人工智能的显著进展,其中以Diffusion-based技术为代表。该技术利用预训练的文本到图像/视频扩散模型进行样式更改、背景交换等任务。然而,在视频编辑中,将源视频的运动转移到编辑后的视频,尤其是确保整个过程中的时间一致性是一个具有挑战性的部分。
大多数视频编辑工具侧重于通过确保时间一致性和动作对齐来保持视频的结构。然而,在处理视频中的形状变化时,这一过程变得无效。为了解决这一问题,新加坡国立大学的Show Lab和Meta的GenAI研究人员引入了VideoSwap框架,该框架使用语义点对应而非密集对应,以对齐主体的运动轨迹并改变其形状。

使用密集对应可以实现更好的时间一致性,但限制了编辑视频中主体形状的变化。尽管使用语义点对应是一种灵活的方法,但在不同的开放世界设置中变化较大,这使得难以训练一个通用的条件模型。
研究人员尝试仅使用有限数量的源视频帧来学习语义点控制,他们发现在源视频帧上优化的点可以对齐主体的运动轨迹并改变主体的形状。
此外,优化后的语义点还可以在语义和低级别变化之间进行转移。这些观察结果为在视频编辑中使用语义点对应提供了依据。
研究人员设计了该框架的方式如下:他们将运动层集成到图像扩散模型中,以确保时间一致性。他们还在源视频中识别了语义点,并利用这些点来传递运动轨迹。该方法仅关注高级语义对齐,从而防止过度学习低级别细节,从而增强语义点对齐。此外,VideoSwap还具有用户点交互,例如删除或拖动点以进行多个语义点对应。
替换效果


研究人员使用潜在扩散模型实施了该框架,并采用AnimateDiff中的运动层作为基础模型。他们发现,与先前的视频编辑方法相比,VideoSwap在同时对齐源运动轨迹、保留目标概念身份的同时实现了显著的形状变化。研究人员还通过人工评估验证了他们的结果,结果清楚地显示,VideoSwap在主体身份、动作对齐和时间一致性等指标上优于其他比较方法。
VideoSwap是一个多才多艺的框架,即使涉及复杂形状的视频编辑也能游刃有余。它在过程中限制了人的干预,并使用语义点对应实现更好的视频主体交换。该方法不仅允许在同时改变形状的同时将运动轨迹与源对象对齐,而且在多个指标上优于先前的方法,展示了在定制视频主体交换方面的最新成果。
论文网址:https://arxiv.org/pdf/2312.02087.pdf
项目网址:https://videoswap.github.io/
- 0000

 0000
0000- 0000
- 0000
- 0000