Stability AI发布30亿参数语言模型StableLM Zephyr 3B 更小更快更节省资源
**划重点:**
- 🚀 Stability AI发布StableLM Zephyr3B,3B参数的大语言模型,优化用于聊天应用,包括文本生成、摘要和内容个性化。
- 🔍 新模型比之前的7B模型更小更快,可在更广泛的硬件上部署,资源占用更低,同时提供快速响应。
- 🌐 使用直接偏好优化(DPO)训练,结合优化的数据集,StableLM Zephyr3B在性能评估中表现出色。
Stability AI以其stable diffusion文本到图像的生成人工智能模型而闻名,但这已不再是该公司的全部业务。
最新发布的StableLM Zephyr3B是一款30亿参数的大语言模型,专为聊天应用场景进行了优化,包括文本生成、摘要和内容个性化。这款新模型是Stability AI早在今年四月首次提及的StableLM文本生成模型的较小、优化版本。
StableLM Zephyr3B的承诺在于,它比7B的StableLM模型更小,带来了一系列好处。由于体积更小,它可以在更广泛的硬件上部署,占用更低的资源,同时仍然提供快速响应。该模型经过优化,特别适用于问答和指令跟随类型的任务。
Stability AI首席执行官Emad Mostaque表示:“相对于以前的模型,StableLM经过更长时间、更高质量数据的训练,例如与LLaMA v27b相比,尽管体积只有其40%,但在基础性能上却能够匹配。”
StableLM Zephyr3B并非全新模型,而是Stability AI定义的现有StableLM3B-4e1t模型的扩展。Zephyr的设计方法受到HuggingFace的Zephyr7B模型的启发。HuggingFace的Zephyr模型是在开源MIT许可下开发的,旨在充当助手。Zephyr采用一种称为Direct Preference Optimization(DPO)的训练方法,StableLM现在也受益于这一方法。
Mostaque解释说,Direct Preference Optimization(DPO)是一种替代以前模型中使用的强化学习的方法,用于调整模型以符合人类偏好。DPO通常用于更大的70亿参数模型,而StableLM Zephyr是首批在更小的30亿参数大小中使用该技术的模型之一。
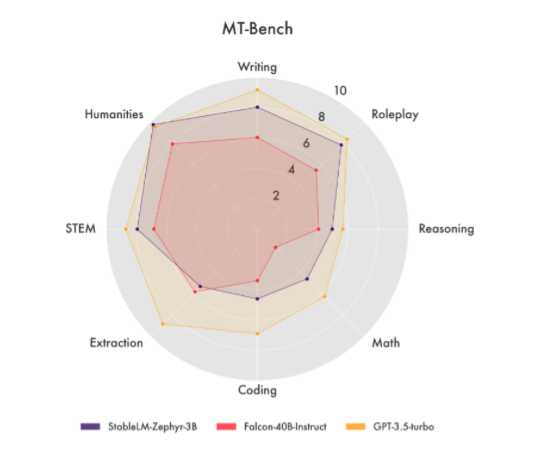
Stability AI使用了来自OpenBMB研究组的UltraFeedback数据集进行DPO。UltraFeedback数据集包含超过64,000个提示和256,000个响应。DPO、较小的体积和优化的数据训练集的组合为StableLM提供了在Stability AI提供的指标中表现出色。例如,在MT Bench评估中,StableLM Zephyr3B能够胜过包括Meta的Llama-2-70b-chat和Anthropric的Claude-V1在内的更大模型。
StableLM Zephyr3B是Stability AI近几个月推出的一系列新模型之一,该初创公司继续推动其能力和工具的发展。虽然公司忙于进入不同领域,但新模型并没有让Stability AI忘记文本到图像生成的基础。上周,Stability AI发布了SDXL Turbo,作为其旗舰SDXL文本到图像stable diffusion模型的更快版本。
Mostaque还明确表示,Stability AI还将推出更多创新。他表示:“我们相信,针对用户自己的数据进行调整的小型、开放、性能良好的模型将胜过更大的通用模型。随着我们新的StableLM模型的未来全面发布,我们期待进一步实现生成语言模型的民主化。”
- 0000
- 0000
- 0000
- 0001
- 0001