CoDi-2:改变交织多模态指令处理和多模态输出生成领域
**划重点:**
1. 🚀 **CoDi-2介绍**:来自加州大学伯克利、Microsoft Azure AI、Zoom和UNC-Chapel Hill的研究人员共同开发的CoDi-2多模态大语言模型,致力于解决生成和理解复杂多模态指令的问题,在主题驱动的图像生成、视觉转换和音频编辑任务方面取得了显著突破。
2. 💡 **模型特性**:CoDi-2在主题驱动的图像生成和音频编辑等任务上超越了其前身CoDi,并采用了包括音频和视觉输入的编码器和解码器的模型架构。其训练过程中融合了来自扩散模型的像素损失以及令牌损失,展现了在风格适应和主题驱动生成等任务中显著的零样本和少样本能力。
3. 🎯 **多模态生成的挑战**:CoDi-2通过利用语言模型(LLM)在编码和生成过程中将模态与语言对齐,成功应对多模态生成中的零样本精细控制、模态交织指令跟随和多轮多模态对话等挑战,展现出卓越的性能和泛化能力。
研究人员合作开发的CoDi-2多模态大语言模型标志着在处理复杂多模态指令生成和理解方面的重大突破。该模型集成了加州大学伯克利、Microsoft Azure AI、Zoom和UNC-Chapel Hill的研究力量,致力于解决主题驱动的图像生成、视觉转换和音频编辑等领域的难题。
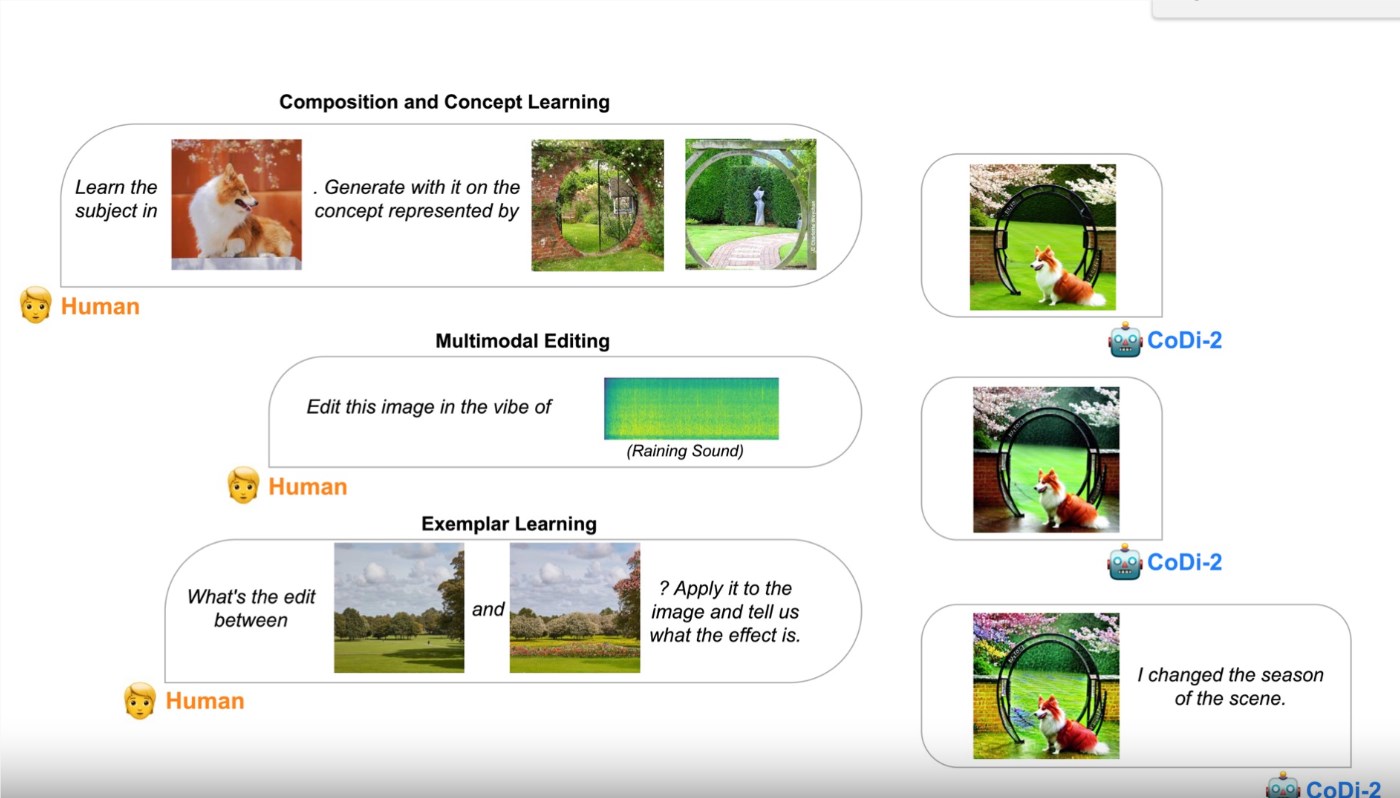
CoDi-2不仅扩展了其前身CoDi的功能,而且在主题驱动的图像生成和音频编辑等任务中表现卓越。其模型架构包括专门用于音频和视觉输入的编码器和解码器。在训练过程中,采用了来自扩散模型的像素损失和令牌损失。CoDi-2在风格适应和主题驱动生成等任务中展现出了显著的零样本和少样本能力。
CoDi-2着重解决了多模态生成中的挑战,强调零样本精细控制、模态交织指令跟随和多轮多模态对话。通过将LLM作为其核心,CoDi-2在编码和生成过程中将各种模态与语言相对应,使其能够理解复杂指令并生成连贯的多模态输出。
模型架构中集成了音频和视觉输入的编码器和解码器,经过对多样生成数据集的训练,CoDi-2在训练阶段利用了来自扩散模型的像素损失和令牌损失。其在零样本能力方面表现出色,不仅在主题驱动的图像生成、视觉转换和音频编辑方面超越了先前的模型,还在新的未见任务中展现了竞争性的性能和泛化能力。
CoDi-2在多模态生成中展示出了广泛的零样本能力,在上下文学习、推理和任意模态生成的多轮互动对话中表现卓越。评估结果显示了其在零样本性能和对新任务的强大泛化能力。在音频处理任务中,CoDi-2的表现卓越,通过在所有指标中获得最低分数,实现了在音轨中添加、删除和替换元素方面的卓越性能。这凸显了在上下文年龄、概念学习、编辑和精细控制方面推动高保真多模态生成的重要性。
CoDi-2是一种先进的AI系统,在包括遵循复杂指令、上下文学习、推理、聊天和不同输入输出模式的各种任务中表现出色。其适应不同风格、基于不同主题的内容生成以及在音频处理方面的熟练操作,使其成为多模态基础建模领域的重大突破。CoDi-2代表了对创建一个全面处理多任务系统的深入探索,即使是尚未经过训练的任务也能轻松处理。
CoDi-2未来的方向计划通过优化上下文学习、拓展对话能力和支持额外的模态来增强其多模态生成能力。它旨在通过使用扩散模型等技术来提高图像和音频的保真度。未来的研究还可能涉及评估和比较CoDi-2与其他模型,以了解其优势和局限性。
项目网址:https://codi-2.github.io/
https://github.com/microsoft/i-Code/tree/main/CoDi-2
链接网址:https://arxiv.org/abs/2311.18775
- 0000
- 0000
- 0000
- 0000
- 0000