研究人员推无微调对齐方法URIAL 1个提示搞定LLM对齐
要点:
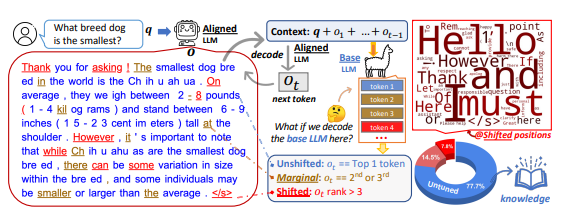
研究者通过分析基础大语言模型(LLM)与其对齐调优版本在 token 分布上的偏移发现,对齐调优主要学习语言风格,而基础 LLM 本身已经具备回答用户查询所需的知识。
提出了一种免微调的对齐方法URIAL,完全利用基础 LLM 的上下文学习(ICL)来实现有效对齐,只需3个恒定的风格化样本和1个系统提示。使用URIAL的基础 LLM在性能上能媲美或超越传统的微调方法。
研究者重新思考了对齐微调的必要性,认为对齐调优只影响基础 LLM 的一小部分,引入URIAL方法和上下文学习能在不进行微调的情况下实现有效对齐。
近期研究发现,对大语言模型(LLM)进行微调对性能有关键影响,但一项新研究表明,免微调的对齐方法也能有效提升LLM性能。
针对大语言模型(LLM)微调的传统方法,研究者发现对齐调优主要学习语言风格,而基础LLM已经具备回答用户查询所需的知识。这引发了对微调必要性的重新思考。
论文地址:https://arxiv.org/pdf/2312.01552.pdf
项目地址:https://allenai.github.io/re-align/
为此,研究人员提出了一种名为URIAL的免微调对齐方法,完全利用基础LLM的上下文学习来实现有效对齐。URIAL只需3个样本和1个系统提示,为对齐提供了一种简单而有效的替代方法。
通过对一组样本进行评估,URIAL方法的性能媲美甚至超越了传统的微调方法,显示了其在对齐方面的有效性。
研究者强调对齐微调可能只是对LLM表面行为的影响,提出了对LLM进行微调的必要性的疑问。这引发了关于如何在无微调的情况下有效对齐LLM的思考。
研究者总结了URIAL方法的优势,并强调上下文学习在对齐中的重要性。这一研究为工程师提供了新的思路,可能减少对LLM进行微调的需求,为构建更高效的AI助手打开了新的可能性。


 0000
0000

 0000
0000- 0000
- 0000
- 0000

