通过这些代码,PyTorch团队让Llama 7B提速10倍
要点:
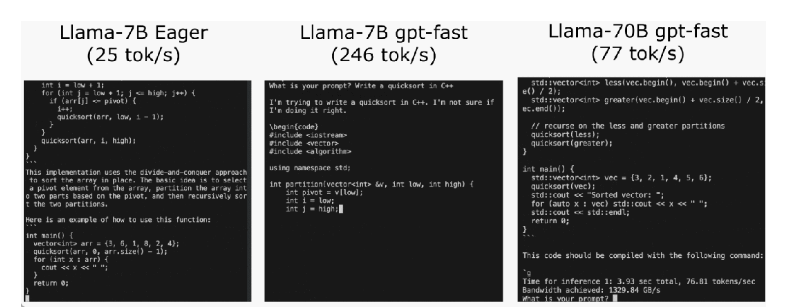
PyTorch团队通过优化技术,在不到1000行的纯原生PyTorch代码中将Llama7B的推理速度提升了10倍,达到了244.7tok/s。
优化方法包括使用PyTorch2.0的torch.compile函数、GPU量化、Speculative Decoding(猜测解码)、张量并行等手段,以及使用不同精度的权重量化,如int8和int4。
通过组合以上技术,包括"compile int4quant speculative decoding"的组合,以及引入张量并行性,实现了在Llama-70B上达到近80tok/s的性能。
近期,PyTorch团队在其博客中分享了一篇关于如何加速大型生成式AI模型推理的文章。该团队以Llama7B为例,展示了如何通过一系列优化技术将推理速度提升10倍,达到了244.7tok/s。
推理性能的初始状态,大模型推理性能为25.5tok/s,效果不佳。然后,通过PyTorch2.0引入的torch.compile函数,以及静态KV缓存等手段,成功减少CPU开销,实现了107.0TOK/S的推理速度。
代码地址:https://github.com/pytorch-labs/gpt-fast
为了进一步提高性能,团队采用了GPU量化技术,通过减小运算精度来加速模型。特别是使用int8量化,性能提升了约50%,达到了157.4tok/s。
然而,仍然存在一个问题,即为了生成100个token,必须加载权重100次。为解决这个问题,团队引入了Speculative Decoding,通过生成一个“draft”模型预测大模型的输出,成功打破了串行依赖,进一步提升了性能。
使用int4量化和GPTQ方法进一步减小权重,以及将所有优化技术组合在一起,最终实现了244.7tok/s的推理速度。
为了进一步减少延迟,文章提到了张量并行性,通过在多个GPU上运行模型,进一步提高了性能,特别是在Llama-70B上达到了近80tok/s。
PyTorch团队通过一系列创新性的优化手段,不仅成功提升了大模型的推理速度,而且以不到1000行的纯原生PyTorch代码展示了这一技术的实现过程。
- 0000
- 0000
- 0000
 0002
0002- 0000


