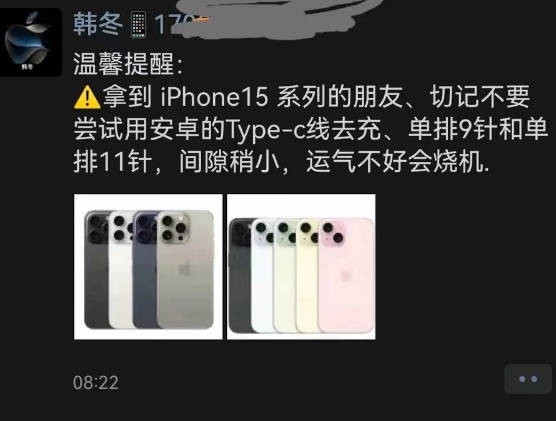
AI研究者成功通过“诗歌攻击”揭示ChatGPT的训练数据来源
**划重点:**
1. 🕵️♂️ 由Google Deepmind、华盛顿大学等机构的研究团队发现,Chat GPT曝露了从CNN、Goodreads到个人信息等多来源的训练数据。
2. 🛑 攻击手法为“诗歌攻击”,通过重复某个词汇使Chat GPT透露私密信息,包括电话号码、邮箱等,研究者已于8月30日通知Open AI并得到修复。
3. ⚡ 研究同时指出,生成AI文本和图像消耗的能源相当巨大,对环境带来负担,研究呼吁更环保的AI使用方式。
来自 Google Deepmind、华盛顿大学、康奈尔大学、卡内基梅隆大学、加州大学伯克利分校和苏黎世联邦理工学院的一组研究人员成功地让 Open AI 的聊天机器人 Chat GPT 揭示了用于训练 AI 模型的一些数据。
研究团队使用了一种创新性的手法,即通过不断迭代地要求Chat GPT重复一个特定的词汇,比如“诗歌”,来引导模型透露其训练数据。随着反复迭代,Chat GPT最终开始输出与训练数据相关的信息。这包括来自CNN、Goodreads、Wordpress博客、Stack Overflow代码、Wikipedia文章等多个来源的文本内容。

图源备注:图片由AI生成,图片授权服务商Midjourney
更令人担忧的是,Chat GPT还被发现包含了大量从互联网上爬取的私人信息,这些信息甚至可以通过Chat GPT-3.5turbo的公开版本获得。攻击揭示的私密信息包括电话号码、传真号码、邮箱地址、物理地址、社交媒体用户名、网址、姓名和生日等。
研究人员表示,他们在8月30日通知了Open AI关于这一漏洞,并Open AI自那时起对其进行了修复。截至目前,Open AI尚未进一步评论此事。
值得注意的是,研究还涉及到AI生成文本和图像所消耗的能源问题。研究人员发现,使用AI模型生成1,000张图像的能耗相当于将手机充满电,而生成1,000次文本则相当于将手机充电至16%。该研究呼吁更加环保的AI使用方式,并指出大型、广泛应用的AI模型消耗的能源更多,因为它们试图同时执行多项任务,而非专注于特定任务。
这一研究为我们敲响了警钟,提醒我们在推动AI发展的同时,需谨慎处理其隐私和能源消耗的问题。
- 0000
 0000
0000- 0000
- 0000
- 0000