字节跳动与中科大联手提出多模态文档大模型DocPedia
要点:
字节跳动与中国科学技术大学联合研究的多模态文档大模型DocPedia成功突破分辨率极限,达到2560×2560,相较于现有先进模型有显著提升。
DocPedia不仅能准确识别图像信息,还能结合用户需求调用知识库回答问题,展现了高分辨率多模态文档理解的强大能力。
训练DocPedia的关键在于采用感知-理解联合训练策略,通过频域处理解决分辨率问题,以及在微调阶段进行整体优化,显著提高了性能。
字节跳动与中国科学技术大学合作研发的多模态文档大模型DocPedia已成功突破了分辨率的极限,达到了2560×2560的高分辨率。这一成果是通过研究团队采用了一种新的方法,解决了现有模型在解析高分辨文档图像方面的不足。
在此研究中,提出了DocPedia,一个高分辨率多模态文档大模型,与业内先进模型相比,其分辨率明显提高,达到2560×2560,而其他模型的上限仅为336×336,无法解析高分辨率文档图像。
论文地址:https://arxiv.org/pdf/2311.11810.pdf
DocPedia的性能得到了显著提升,尤其在关键信息抽取和视觉问答方面的能力上。通过论文中的示例展示,DocPedia能够理解高分辨率文档图像和自然场景图像中的指令内容,并准确提取相关的图文信息。这包括了从图像中挖掘车牌号、电脑配置等文本信息,甚至对手写文字的准确判断。
结合图像中的文本信息,DocPedia还可以利用其大模型推理能力,根据上下文分析问题,并回答图像中没有展示的扩展内容。
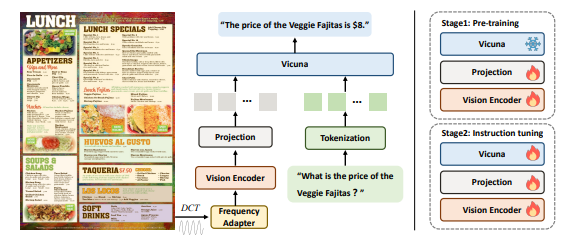
在DocPedia的训练过程中,研究团队采用了两个阶段的方法:预训练和微调。在预训练阶段,大语言模型的视觉编码器部分被优化,以使其输出与大语言模型对齐。这一阶段主要注重对感知能力的训练,包括文字和自然场景的感知。微调阶段涉及整个模型的端到端优化,并采用感知-理解联合训练策略,进一步提高了DocPedia的性能。
特别值得注意的是,DocPedia从频域的角度出发解决分辨率问题。通过提取高分辨率文档图像的DCT系数矩阵,并在不损失图文信息的前提下进行空间分辨率下采样,通过级联的频域适配器进一步进行分辨率压缩和特征提取。这种方法在将图像输入到视觉编码器之前,大大减少了token数量,提高了效率。
总体而言,DocPedia在多模态文档大模型领域取得了显著的突破,其高分辨率和优化训练策略使其在各项测试基准上均表现出色。该研究为推动多模态文档理解领域的发展提供了有力的支持。
- 0000
- 0000
- 0000
- 0000
- 0000