GPT-4等大模型更能记住版权书籍的内容 容易导致侵权和社会偏见问题
一项研究指出了当今大型语言模型的另一个潜在版权问题和文化挑战:一本书越有名和越受欢迎,语言模型就越能记住其内容。
加州大学伯克利分校的研究人员测试了ChatGPT、GPT-4和 BERT 的“背诵”能力。根据这项研究,语言模型记住了“大量受版权保护的材料”。一本书的内容在网上越受欢迎多,语言模型就越能记住其内容。
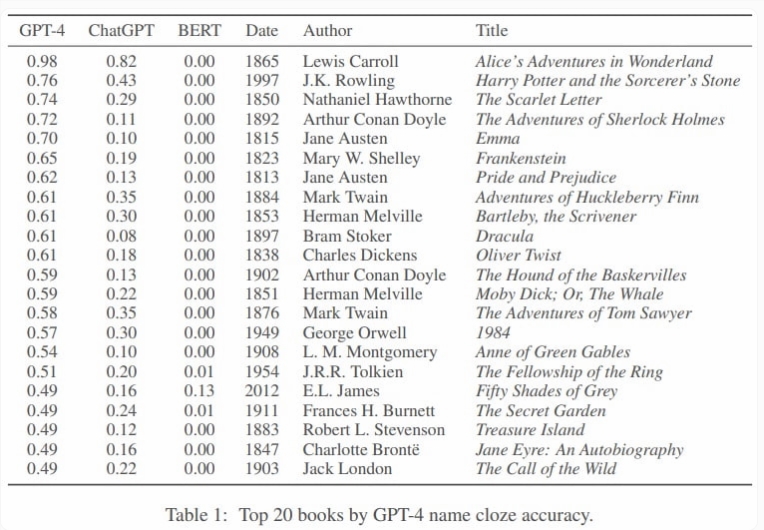
根据这项研究,OpenAI 的模型特别擅长记忆科幻小说、奇幻小说和畅销书。其中包括 《1984》、《德古拉》和《弗兰肯斯坦》等经典作品,以及《哈利波特与魔法石》等近期作品。
研究人员将谷歌的 BERT 与 ChatGPT 和 GPT-4进行了比较。“BookCorpus”是一套据称由未知作者创作的免费书籍的训练集,其中包括《丹·布朗》或《五十度灰》的作品。BERT 会记住这些书中的信息,因为这些都数据的一部分。
研究人员写道,一本书在网络上出现的次数越多,大型语言模型对它的记忆就越详细。记忆决定了语言模型执行有关一本书的下游任务的能力:一本书越为人所知,语言模型就越有可能成功地执行诸如命名出版年份或正确识别书中字符等任务。
研究人员主要关注的不是版权问题。相反,他们关心的是使用大规模语言模型进行文化分析的潜在机会和问题,特别是通俗科幻小说和奇幻作品中的共同叙事所造成的社会偏见。
文化分析研究可能会受到大规模语言模型的严重影响,并且根据培训材料中书籍的存在而产生的不同表现可能会导致研究出现偏差。
在此背景下,研究团队有一个明确的诉求:训练数据的公开。
研究人员写道,这些模型特别擅长从流行的叙述中学习,但这些叙述并不代表大多数人的经历。这一事实如何影响大规模语言模型的输出,以及它们作为文化分析工具的有用性,需要进一步研究。
此外,该团队表示,研究表明流行书籍并不是大型语言模型的良好性能测试,它们可能会表现更为出色。
- 0000
- 0000
- 0003
- 0000
- 0001


