Tanuki通过自动模型蒸馏 轻松构建LLM技术驱动的应用
Tanuki.py是一个用于构建LLM(Large Language Models)驱动应用的工具库。该库旨在通过自动模型蒸馏,实现应用在使用过程中的成本和延迟的逐渐降低,最多可达到90%的成本降低和80%的延迟降低。
Tanuki的使用非常简单,用户只需使用@tanuki.patch和@tanuki.align装饰器即可将LLM引入Python函数。@tanuki.patch用于将LLM嵌入函数体,而@tanuki.align用于通过测试驱动对函数的行为进行对齐。对齐的目的是确保LLM输出与期望的输出一致,从而提高可预测性。
项目地址:https://github.com/Tanuki/tanuki.py
这个工具库的特色之一是对类型的支持。用户可以使用类型提示,如Python基本类型、Pydantic类、Literals、Generics等,确保LLM输出符合函数的类型约束,防止出现意外错误。
除了类型支持,Tanuki还提供了对RAG(Retrieval Augmented Generation)的支持,允许用户通过嵌入输出来集成下游RAG实现。这样,用户可以在降低成本和延迟的同时提高对长篇内容的性能。
在使用Tanuki构建LLM-powered函数时,用户可以通过对齐函数来验证期望的输出。这种测试驱动的对齐方法有助于确认函数是否符合预期行为,捕获行为细微差异,并支持迭代开发。
Tanuki的工作原理是在开发过程中调用tanuki-patched函数时,会使用n-shot配置的LLM生成类型化的响应。响应经过后处理,确保返回正确的类型。这些响应将作为未来训练数据存储,随着数据量的增加,将使用更小的模型进行蒸馏,从而实现更低的计算成本、更低的延迟,无需额外的MLOps努力。
Tanuki.py提供了一种简单而强大的方式,通过LLM构建应用,并通过自动模型蒸馏实现成本和性能的优化。其类型感知、RAG支持和测试驱动的对齐方法使其成为构建可靠、可预测、逐渐优化的LLM-powered应用的理想选择。
- 0000
- 0000

 0000
0000- 0000
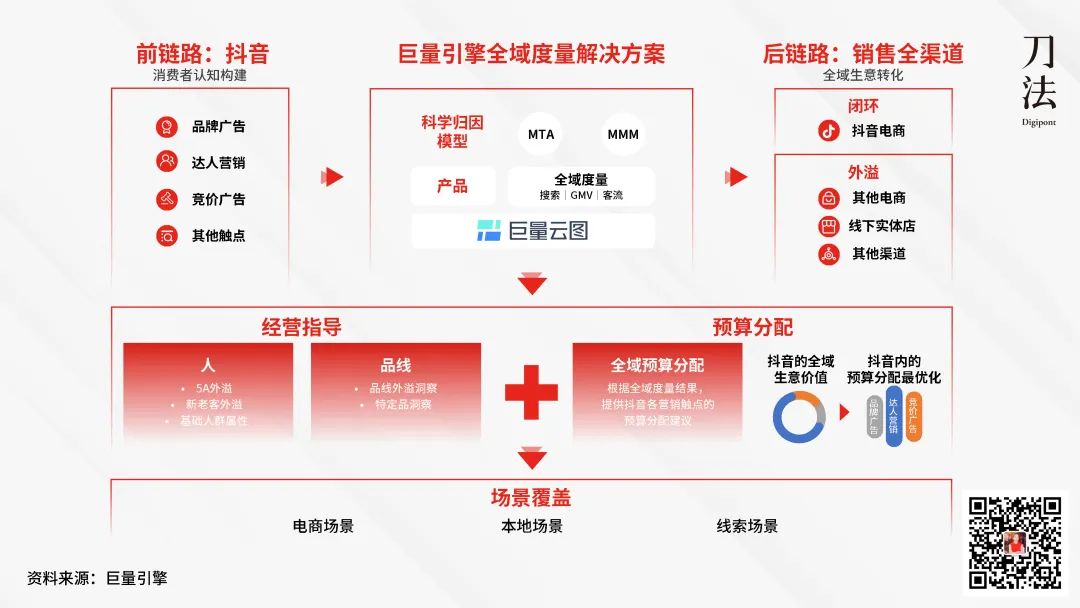

 0000
0000


