英特尔推Extension for Transformers工具包 大模型推理性能提升40倍
要点:
通过该工具包,使用英特尔® 至强® 处理器可实现大型语言模型(LLM)推理性能加速达40倍,满足各种应用需求。
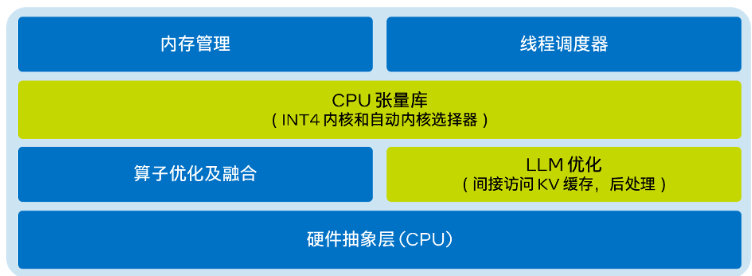
工具包提供轻量级但高效的LLM推理运行时,优化了内核,支持多种量化选择,提供更优的KV缓存访问和内存分配策略,显著提升了性能。
工具包攻克了对话历史、输出长度有限以及效率低下等聊天场景应用难题,通过引入流式LLM技术优化内存使用和推理时延。
在当前技术发展的背景下,英特尔公司推出的Extension for Transformers工具包成为一个重要创新,实现了在CPU上对大型语言模型(LLM)推理性能的显著加速。该工具包通过LLM Runtime技术,优化了内核,支持多种量化选择,提供更优的KV缓存访问和内存分配策略,使得首个token和下一个token的推理速度分别提升多达40倍和2.68倍。这一技术的推出,极大地满足了不同场景对于LLM推理性能的需求。
项目地址:https://github.com/intel/intel-extension-for-transformers
在性能测试方面,通过与llama.cpp进行比较,LLM Runtime在输入大小为1024时能够实现3.58到21.5倍的性能提升,而在输入大小为32时,提升为1.76到3.43倍。同时,工具包还通过验证了多个模型的INT4推理准确性,表明在性能提升的同时准确性损失微小。
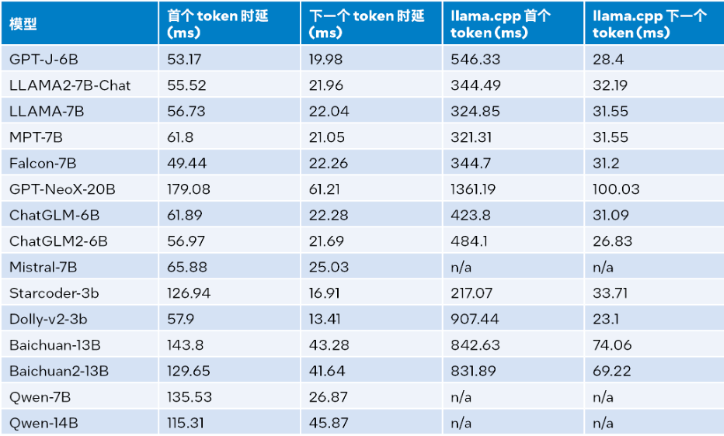
然而,不仅仅是性能的提升,工具包还在聊天场景中应用方面取得了显著成果。通过引入流式LLM技术,解决了对话历史、输出长度有限和效率低下等应用难题,使得LLM在聊天场景中更加实用。这一技术的特性,包括对话历史的纳入和输出长度的优化,使得工具包在解决聊天场景难题方面具有先进性和前瞻性。
英特尔® Extension for Transformers工具包在大型语言模型推理性能的提升以及聊天场景应用方面的创新成果,标志着对于人工智能领域的进一步推动。通过不断引入先进的技术和解决实际问题的能力,该工具包展现了英特尔在人工智能领域的领先地位,为未来的发展提供了强有力的支持。
- 0000
- 0001
- 0002
- 0001
- 0001