视频编辑利器Pix2Video 无需训练微调
站长网2023-11-29 18:17:040阅
要点:
本文提出了一种基于预训练的图像扩散模型的视频编辑方法,实现文本引导的编辑,无需训练或微调,可推广到广泛编辑领域。
通过自注意力特征注入,该方法在每个扩散步骤中注入前一帧的特征,以保持外观的一致性,解决了视频编辑中的外观变化问题。
引入了潜在更新机制,通过能量函数提高一致性,增强了算法的时间稳定性,减少了时间闪烁的影响。
Pix2Video是一项基于预训练的图像扩散模型的视频编辑研究,致力于实现文本引导的编辑,无需繁琐的训练或微调。该方法通过自注意力特征注入,在每个扩散步骤中注入前一帧的特征,以确保编辑后的视频外观连贯一致,解决了编辑过程中可能出现的外观变化问题。
此外,为提高算法的时间稳定性,引入了潜在更新机制,通过能量函数增强一致性,有效减少了时间闪烁的影响。
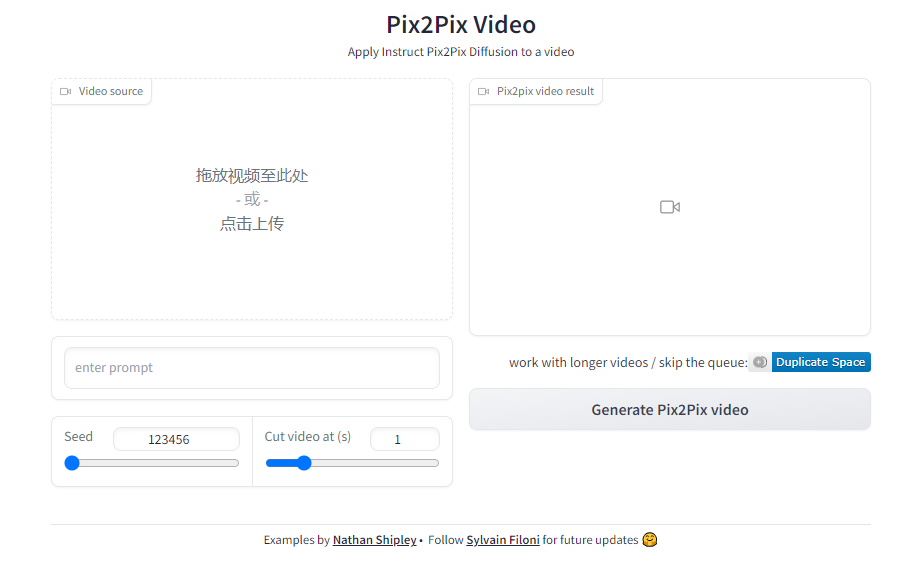
项目地址:https://huggingface.co/spaces/fffiloni/Pix2Pix-Video
大规模图像生成扩散模型在静态图像生成方面表现出色,但在处理视频编辑时面临挑战。为了应对这一挑战,Pix2Video采用了深度条件稳定扩散模型,通过对每帧进行深度预测,并将其作为模型的额外输入,以捕捉运动动态和几何变化。
自注意力特征注入是该方法的关键步骤,通过在解码器层执行特征注入,确保在保持外观一致性的同时避免高频结构变化。此外,为提高时间稳定性,潜在更新机制通过额外的指导来更新隐变量,通过能量函数增强一致性,降低了时间闪烁的影响。
Pix2Video的实验证明了其方法的有效性,并与四种不同的先前工作进行了比较,证明了文本引导的视频编辑是可能的,无需复杂的预处理或视频个性化微调。该研究为实时互动视频编辑领域提供了一种创新方法,具有潜在的应用前景。
0000
评论列表
共(0)条相关推荐
- 0000
 0000
0000- 0000
 0003
0003- 0000

