盘点近几年的互联网宕机事件,都是啥原因?
“滴滴滴滴滴滴等待”,从昨天晚上到今天中午,滴滴崩了难住了不少打工人。
这次宕机持续近12个小时,算是滴滴近年来瘫痪时间最长的一次故障。
滴滴2023年第三季度财报显示,单季度中国出行业务总交易额为725亿元,日均单量达到3130万单。据此,有媒体估计将会让滴滴损失过千万的订单量和超4亿的交易额。
而除了滴滴外,阿里云在不到10天的时间里也出现了两次故障。
第一次是11月12日下午5点多,阿里云出现异常,随之“淘宝又崩了”“闲鱼崩了”“阿里云盘崩了”“钉钉崩了”等话题相继登上微博热搜。
原因是2023年11月12日17:44起,阿里云产品控制台访问及API调用出现出现使用异常,阿里云工程师正在紧急介入排查。当天晚上7点20左右恢复正常。
第二次就是昨天,阿里云再次出现故障,不到两个小时后得到修复。
阿里云声明称11月27日09:16起,阿里云监控发现北京、上海、杭州、深圳、青岛 、香港以及美东、美西地域的数据库产品(RDS、PolarDB、Redis等)的控制台和OpenAPI访问出现异常,实例运行不受影响。经过工程师紧急处理,访问异常问题已于当日10:58恢复。
而事实上,阿里云在近几年曾出现多次事故。从2018年至2022年的5年时间里,阿里云曾有3次大事故。
2022年12月18日,阿里云爆发香港Region可用区C大规模服务中断事件,导致多个香港及澳门站点受到影响。当时阿里云坦言:“这对很多客户的业务产生重大影响,也是阿里云运营十多年来持续时间最长的一次大规模故障。”
后来,阿里云发布了事件说明,公告显示,冷机系统故障恢复时间过长、现场处置不及时导致触发消防喷淋、客户在香港地域新购ECS等管控操作失败、故障信息发布不够及时透明是导致此次宕机时间长、规模大的四大重要原因。
下面我们再来盘点下近几年来影响较大的宕机事件。
先看看国际宕机事件:
Facebook史上最严重宕机
长达7小时,市值蒸发数百亿
2021年10月5日,Facebook、Messenger、Instagram和WhatsApp等Facebook旗下应用均出现故障。
据了解,此次宕机长达7个小时,刷新了 Facebook 自2008年以来的最长宕机时长。
此次宕机影响到全球数十个国家和地区用户,Facebook几乎所有的产品都受到波及,甚至内网都无法使用。Facebook拥有几十亿用户,影响范围不可想象。
宕机期间,大量用户涌向了Twitter、Telegram等其他应用,又进一步导致这些应用程序的服务器崩溃。
后来Facebook对宕机原因进行了说明。
声明中称:“据我们工程团队的了解,协调数据中心之间网络流量的主干路由器的配置变化导致了通信中断,由此对我们数据中心的通信方式产生了连带影响,使我们的服务陷入停顿。”
当日Facebook股价盘中暴跌6%,市值减少数百亿美元,扎克伯格个人财富一日蒸发逾60亿美元。
当时有媒体报道,专家估计Facebook、Instagram、WhatsApp全球服务中断一小时就将给全球经济造成1.6亿美元的损失。
ChatGPT和API服务出现严重停机
CEO公开致歉
根据网络状况监测网站Downdector的数据显示,大概从11月8日北京时间周三晚22点左右开始,出现大量网友报告OpenAI的ChatGPT和API(提供给开发者搭建第三方服务的应用程序接口)全都无法使用。整个故障的时间大致持续了100分钟。
OpenAI也将这次的事件定义为“严重停机”(Major Outage)。公司在北京时间11月8日21点54分宣布服务出现问题。最终在当天23点33分,OpenAI确认已实施修复措施,服务开始逐渐恢复。
为此,OpenAI CEO山姆·奥特曼在X(原推特)上发表公开致歉称,本周发布的新功能遇到远超预期的使用量。公司原计划在周一为所有订阅者启用GPT服务,但目前还无法实现。奥特曼进一步表示,由于负载原因,短期内可能还会出现服务不稳定的情况。
苹果公司也多次宕机
作为全球最受瞩目的科技公司,苹果也有过宕机事件。
在去年苹果曾多次出现宕机事故,一月份有1次,3月份有2次,8月份还有一次。
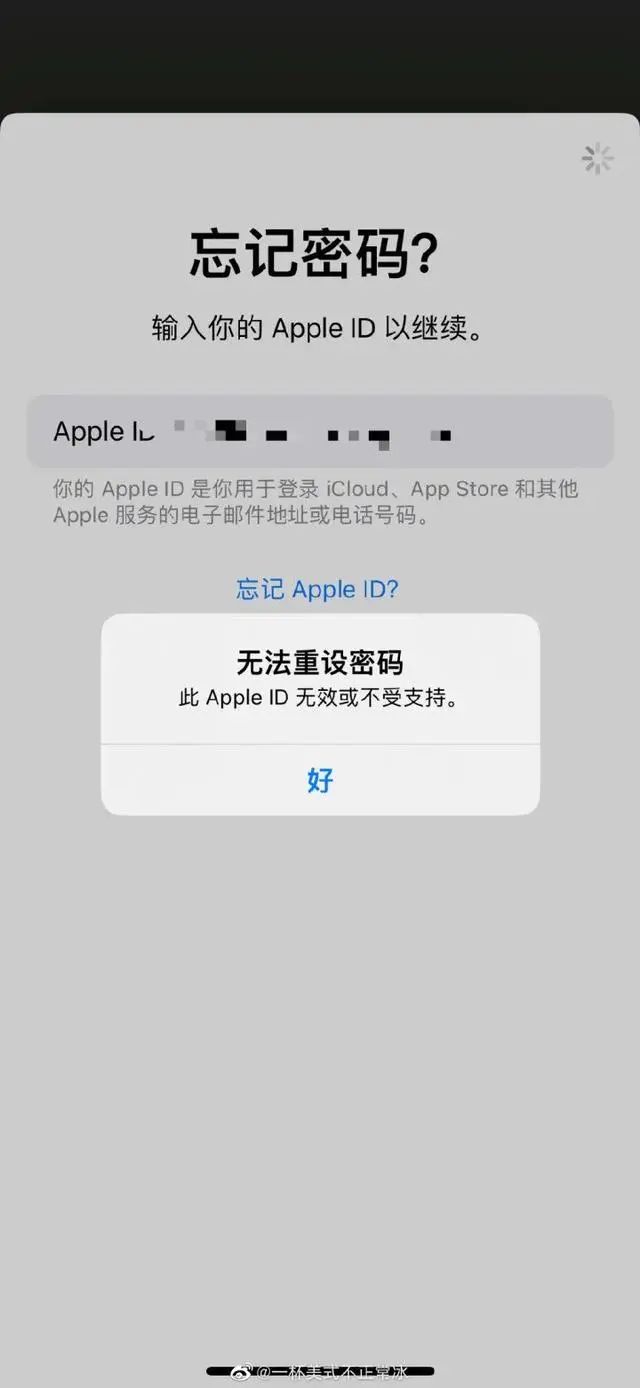
2022年1月26日,苹果iCloud服务遭遇大范围宕机,受影响严重的地区有纽约、芝加哥、洛杉矶。
同年3月23日,苹果再次出现服务器宕机。来到8月份,苹果的一些iCloud服务发生了中断。
2023年5月11日,苹果全球服务经历了55分钟的大规模宕机,导致许多用户的 Apple ID / iCloud 账户突然登出,无法登录。宕机的原因是数据中心的严重故障,导致苹果公司的多项服务无法正常运行,包括 iCloud、App Store、iTunes 等。
谷歌曾一年就4次宕机
谷歌也经常发生宕机事件。
2022年8月8日,美国爱荷华州康瑟尔布拉夫斯的谷歌数据中心发生电力事故,导致3名电工严重烧伤。
据媒体报道,3名电工在数据中心大楼附近的变电站工作时,突然发生了电弧闪光,事故造成全球40多个国家/地区的至少1338台服务器中断服务,谷歌搜索遭遇全球性宕机。
此外,在2020年谷歌就发生了4次宕机事件。
特斯拉全球性宕机
2020年9月,特斯拉系统遭全球性宕机。
从美东时间9月23日11点开始,特斯拉车主便无法通过手机App连接到汽车上。同样的问题也发生在特斯拉的能源产品上,特斯拉太阳能和Powerwall储能电池用户无法监控他们的系统。
有用户在宕机追踪网站Down Detetor上表示,特斯拉App在iPhone上显示已经“冻结”,卸载、重新下载了后App则显示“出现错误”。受到影响的车主大部分来自美国,英国、德国、俄罗斯等欧洲国家的车主也报告了类似的问题,一些中国车主也反映了特斯拉App手机钥匙断开连接的问题。
有网友在推特求救称,自己在一个沙漠的超级充电桩,但被锁在Model3车外了,特斯拉App无法连接到车上,已经拨打紧急道路救援电话快两小时了。
这并非特斯拉第一次出现全系统的宕机。早在2018年4月21日,从下午开始一直到次日早上,众多特斯拉车主经历了长时间的App宕机。当时,特斯拉承认出现了问题并表示当日晚间已经修复,但许多车主在次日早上仍在经历同样的问题。而2017年3月7日,特斯拉的APP和API停机几乎长达24小时。
云计算巨头OVH数据中心大火
导致360万个网站下线
2021年3月份,欧洲云计算巨头OVH位于法国斯特拉斯堡的数据中心发生严重火灾,该区域总共有4个数据中心,其中一个数据中心被完全烧毁。大火6个小时才被扑灭。
据了解,此次多达360万个网站下线。
受到此次大火影响的客户包括欧洲航天局的数据与信息访问服务ONDA项目,此项目负责为用户托管地理空间数据并在云端构建应用程序。Rust旗下的游戏工作室Facepunch Studios证实,有25台服务器被烧毁,他们的数据已在这场大火中全部丢失。即使数据中心重新上线后,也无法恢复任何数据。
美国民航系统瘫痪
数百架次航班取消
2023年1月11日,美国民航系统于当地时间周三早间瘫痪,导致当日9时全美所有航班禁飞,超过4000架次国内国际航班延误,据 FlightAware 数据显示,截至美东时间8时50分,全美约698架次航班取消。
这次故障可能源于飞行任务通知系统的一个文件损坏,而在紧急情况下使用的备份系统也发现了损坏文件,美国联邦航空管理局被迫重启系统,导致航班大面积延误或取消。
再来看看国内宕机事件:
唯品会宕机12小时
损失超亿元
今年3月29日,“唯品会崩了”登上热搜,由于崩溃时间太长,影响了很多消费者无法正常下单,唯品会官方对此回应称,因系统短时故障,主站“加购”等功能或出现异常。
6月5日,唯品会发布“关于329机房宕机故障处理公告”,公告称,3月29日(00:14-12:01)南沙IDC冷冻系统故障,导致机房设备温度快速升高宕机,造成线上商城停止服务。此次事故影响时间持续12个小时,导致唯品会业绩损失超亿元,影响客户达800万,唯品会将此次故障判定为P0级故障。

公告指出,唯品会决定对此次事件严肃处理,对应部门的直接管理者承担此次事故责任,基础平台部负责人予以免职做相应处理。
招商证券三个月崩2次
2022年3月和5月,招商证券出现了2次系统崩溃情况。
3月14日早间开盘后,陆续有网友在社交平台反映招商证券交易系统出现系统故障,包括无法成交、无法撤回等。随后,“招商证券崩了”登上微博热搜。
5月16日,有大量投资者再次反映招商证券系统崩溃,电脑和手机都无法登录。
事实上除了招商证券,今年3月份,东方财富证券交易软件在一个交易日内出现“两连崩”。
语雀宕机7小时
影响数千万用户
2023年10月23日,蚂蚁集团旗下的在线文档编辑与协同工具语雀发生服务器故障。从故障发生到完全恢复正常,语雀整个宕机时间将近8小时。
语雀方面表示,10月23日下午,服务语雀的数据存储运维团队在进行升级操作时,由于新的运维升级工具bug,导致华东地区生产环境存储服务器被误下线。
百度宕机系运营商DNS问题
2018年11月9日,百度网站疑似崩溃,移动端和网页端均无法打开。对此百度方面回应称,系运营商DNS问题,影响北京联通部分用户。
据了解,本次事故主要涵盖北京地区的联通用户。具体表现为无法打开百度移动端和网页端。目前,百度方面称,已与运营商方面联动,目前已经定位并正在加紧修复该问题。
宕机原因都有啥?
服务器宕机的原因五花八门,常见原因有:
硬件故障:服务器的硬件组件(如电源、内存、硬盘、主板等)出现故障,导致系统无法正常工作。
软件问题:操作系统、应用程序或驱动程序出现错误、崩溃或冲突,导致系统不稳定甚至宕机。
资源耗尽:CPU、内存、磁盘空间或网络带宽等资源耗尽,使服务器无法继续运行。
网络问题:网络故障、网络攻击(如DDoS攻击)或网络设备问题导致服务器无法正常访问或通信。
电力问题:电源不稳定、电压波动、电力供应中断等问题导致服务器关机或宕机。
安全问题:恶意攻击、病毒、恶意软件或黑客入侵导致服务器宕机或无法正常工作。
操作错误:误操作、配置错误或不当的系统管理操作可能导致服务器不稳定或宕机。
数据库问题:数据库故障、死锁、数据损坏等问题可能影响应用程序和服务器的正常运行。
温度问题:过高的温度可能导致服务器硬件损坏或系统关机,尤其是在散热不良的情况下。
文中提到的例子中,很多都有涉及。比如ChatGPT就是典型的服务器负载过大;美国民航系统是文件损坏,不得不重启系统;还有唯品会是运行环境的冷却系统故障,高温导致机房宕机。
除了以上原因,我们还能注意到火灾等危险也是服务器面临的重要考验。
当然服务器宕机是个复杂的问题,可能受到多重因素的影响,背后的原因也比我们想象的复杂。
有人认为最近频繁的宕机或许和人员优化有关,得出人才缺失的结论。这种说法看似有点道理,但实则没有有力依据。
对一个成熟公司来说,边缘业务可能因为人才流失受到较大影响,而核心业务根本不会。
你说是不是呢?
- 0000


 0000
0000- 0001
- 0000
- 0000



