AI视野:Stability.ai开源SDXL Turbo;Pika Labs1.0版发布;字节跳动ChitChop在海外上线;Keras3.0正式发布;法院判决AI生成图片具备版权
🤖📱💼AI应用
Stability.ai发布开源文生图模型SDXL Turbo
文生成图AI平台Stability.ai发布开源SDXL Turbo,图像生成实时响应,仅需1秒。SDXL Turbo基于全新对抗扩散蒸馏技术(ADD),将生成步骤减至1-4步,保持高质量。性能测试显示,SDXL Turbo在1步骤击败LCM-XL的4步骤和SDXL的50步骤。虽有局限,只能用于学术研究,生成512x512固定像素图片,但技术突破可助中小企业低成本应用。
开源地址:https://github.com/Stability-AI/generative-models
在线体验地址:https://clipdrop.co/stable-diffusion-turbo
论文地址:https://stability.ai/s/adversarial_diffusion_distillation.pdf
【AiBase提要:】
🚀 SDXL Turbo发布:Stability.ai宣布开源SDXL Turbo,实现文生成图实时响应,1秒生成图片。
🌐 技术突破:基于对抗扩散蒸馏技术,SDXL Turbo将生成步骤从50减至1-4步,保持高图像质量。
💼 应用范围:虽局限于学术研究,SDXL Turbo技术突破可助中小企业以低成本进行图像生成应用。
Pika Labs1.0版发布
AI初创公司Pika Labs正式发布了其令人印象深刻的AI视频生成器的1.0版本,为视频创作带来了全新的体验。

Pika Labs体验网址:https://top.aibase.com/tool/pika-labs
【AiBase提要:】
Pika Labs发布1.0版AI视频生成器,支持多种风格视频创作。
Pika Labs成功融资5500万美元,由知名投资者领投。
Pika Labs1.0支持用户上传视频二次生成和编辑,而且还能局部编辑视频内容
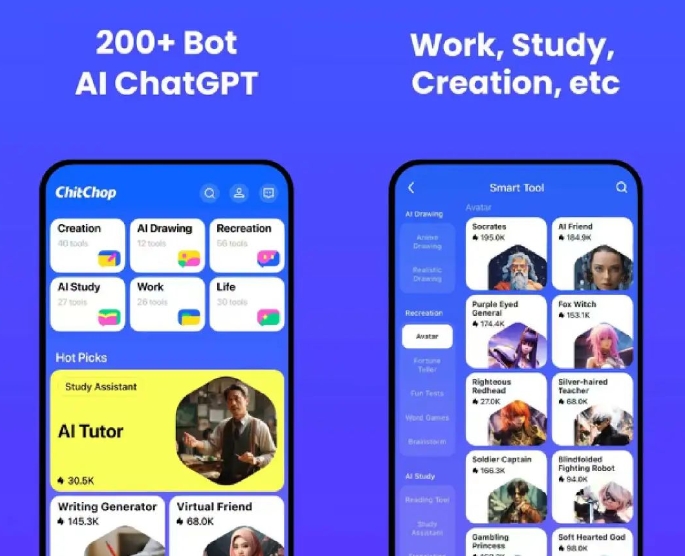
字节跳动ChitChop在海外上线
字节跳动推出的大模型产品“ChitChop”在海外上线,由POLIGON开发和运营,提供多达200 的智能机器人服务,支持创作、工作、AI画画、娱乐、AI学习和生活等六大场景,具备语音输入和文件分析功能。
【AiBase提要:】
🤖 ChitChop是字节跳动的人工智能助理工具,提供200 智能机器人服务。
🖋️ 产品支持创作、工作、AI画画、娱乐、AI学习和生活等六大场景。
🎙️ ChitChop具备语音输入功能,能自动识别语音内容,并可进行文件分析和讨论。
📰🤖📢AI新鲜事
OpenAI介入调查:GPT-4在编写代码上偷懒
GPT-4最新版本因偷懒不愿编写完整代码,用户抱怨频出,引起广泛关注和调查。
【AiBase提要:】
😞 GPT-4最新版本存在编写代码懒惰的问题,用户反映在实际需求中难以得到满足。
🤖 用户反馈GPT-4在解释问题上花费过多时间,而不提供实际可运行代码,引发不满。
🔍 OpenAI已介入调查,并表示将借助用户提供的例子加以改进。
法院判决AI生成图片具备版权
北京互联网法院首次就AI生成图片领域著作权侵权案作出一审判决,认定AI生成的图片具备独创性和智力投入,应受著作权法保护,为该领域著作权保护树立了重要判例。
【AiBase提要:】
🤖法院首次确认AI生成图片具备独创性和智力投入,应受著作权法保护。
🧠在创作过程中,法院强调智力投入主要来自人而非人工智能模型。
🖼️判决对涉案图片的智力成果、独创性、作品性质及著作权归属等进行详细解释,对AI生成图片领域著作权保护具有重要意义。
vivo S18系列将首批搭载蓝心AI大模型
vivo宣布S18系列将成为首批采用AI大模型技术的手机,搭载自研蓝心大模型,参数量级涵盖十亿、百亿、千亿。S18将采用骁龙7Gen3处理器,而S18Pro升级为天玑9200处理器。
【AiBase提要:】
🚀 技术领先: vivo S18系列引领潮流,首批搭载覆盖十亿至千亿参数级别的蓝心AI大模型技术。
💡 卓越配置: S18搭载骁龙7Gen3处理器,曲面屏、超光感人像镜头,而S18Pro升级至天玑9200,支持Wi-Fi7等先进配置。
🌐 全面布局: vivo不仅在硬件上创新,还推出了蓝心小V助理和蓝心千询APP,拓展了基于AI大模型的应用场景。
谷歌搜索展示AI生成图片替代了真实照片
最新报道指出,谷歌搜索结果中以色列传奇歌手卡玛卡维沃·奥莱的照片实际上是由人工智能生成的,引发了对搜索准确性的担忧。
【AiBase提要:】
🔍 谷歌搜索显示卡玛卡维沃·奥莱的照片实为AI生成,替代了真实照片。
🤖 谷歌表示正在改进Knowledge Panels,但对问题尚未解决。
🌐 网页指责Google对AI生成的虚假信息回应不足,呼吁公司解决问题。
亚马逊宣布推出新的人工智能芯片Trainium2
亚马逊AWS推出新的人工智能芯片「Trainium2」,旨在构建和运行AI应用程序,同时深化与英伟达的合作,提供对Nvidia最新芯片的访问。
【AiBase提要:】
🚀 双管齐下策略: 亚马逊计划推出Trainium2人工智能芯片,同时提供对Nvidia最新芯片的访问,以满足不断增长的AI应用需求。
💡 性能提升: Trainium2芯片将使AI模型性能提高四倍,为公司如OpenAI、Databricks等提供更强大的训练工具。
🌐 多元选择: 亚马逊强调其云计算服务AWS的多元选择,包括Graviton4处理器和Nvidia GPU,以满足客户对成本效益高的云服务的需求。
一男子用AI工具洗稿竞争对手文章 “窃取”数百万的页面浏览量
人工智能生成工具在SEO领域引发争议,Content Growth创始人通过AI文本生成器成功窃取360万流量,引发用户质疑和道德担忧。
【AiBase提要:】
🔄 互联网时代,强大的文本生成器如ChatGPT颠覆传统SEO,引发人工智能生成内容浪潮。
🤨 Content Growth创始人通过AI文本生成器实施SEO“抢劫”,引发用户强烈愤怒和道德质疑。
🤔 使用Byword等人工智能生成器清洗现有内容,可能欺骗搜索引擎,呼吁对人工智能内容进行监管和审查。
麻省理工学院推GenSim项目:利用大语言模型编写机器人新任务
麻省理工学院的“GenSim”项目利用大型语言模型如GPT-4,通过自动生成新任务或详细说明所需行为的每个步骤,扩大了机器人可以接受培训的仿真任务范围,为机器人学习提供更广泛的模拟任务。
【AiBase提要:】
🌐 MIT CSAIL的“GenSim”项目通过大型语言模型生成新任务或详细说明机器人行为步骤,拓展了机器人在仿真任务中的培训范围。
🤖 GenSim系统具有目标导向和探索两种模式,利用LLM生成任务描述和行为代码,成功训练机械臂执行新任务,如高速放置彩色积木。
💡 经过人类预训练后,GenSim自动生成了100种新行为,相比手动编写任务的基准测试,展示了在构思新型机器人活动方面的潜力。
亚马逊推出AI聊天机器人Amazon Q
亚马逊在re:Invent大会上发布了面向AWS客户的AI聊天机器人「Amazon Q」,可提供广泛的解决方案和操作建议,涵盖业务智能、编程和配置等多个领域。
【AiBase提要:】
🤖 Amazon Q是面向AWS客户的聊天机器人,起始价格每用户每年20美元,能回答广泛问题。
🔗 可连接到各应用程序,学习企业各方面信息,生成内容,提供可视化选项。
🔐 重视隐私,Q仅返回用户有权查看信息,管理员可控制和过滤答案。
🤖📈💻💡大模型动态
北大提出Chat-UniVi视觉语言大模型
Chat-UniVi是由北大和中山大学研究者提出的统一视觉语言大模型,在短短三天训练内获得130亿参数,通过动态视觉token和密度峰聚类算法实现统一视觉表征,在多任务中表现卓越。

项目地址:https://github.com/PKU-YuanGroup/Chat-UniVi
【AiBase提要:】
🌐 模型简介: Chat-UniVi是北大和中山大学研究者提出的视觉语言大模型,仅需三天训练即可获得130亿参数,实现统一的视觉表征。
🚀 核心方法: 采用动态视觉token和密度峰聚类算法,大幅减少视觉token数量,提高模型性能,在多任务中超越其他大型模型。
📈 实验成果: Chat-UniVi在图片、视频理解以及问答任务中表现卓越,使用更少的视觉token达到与其他大模型相媲美的性能水平,并开源了代码、数据集和模型权重。
新加坡国立大学开源多模态语言模型 NExT-GPT
新加坡国立大学发布的开源多模态语言模型 NExT-GPT,通过处理文本、图像、视频和音频等多样化输入,推动了多媒体人工智能应用的发展,为开发者提供强大支持。
【AiBase提要:】
🌐 多模态能力: NExT-GPT 提供强大的多模态语言模型,能处理文本、图像、视频和音频,拓展了人工智能应用领域。
🧠 架构与训练: 采用三层架构,包括线性投影、Vicuna LLM 核心和模态特定的转换层,通过 MosIT 技术进行中间层训练,降低训练成本。
🌟 开源贡献: NExT-GPT 的开源使研究者和开发者能够创建能够无缝集成文本、图像、视频和音频的应用,为多媒体人工智能应用提供了重要贡献。
研究人员发布Starling-7B:基于AI反馈的大语言模型
UC伯克利发布基于AI反馈强化学习的Starling-7B大语言模型,采用RLAIF技术,在性能上媲美GPT-3.5,通过基准测试表现出色,迈向更人性化的应用。
项目网址:https://huggingface.co/berkeley-nest/Starling-LM-7B-alpha
【AiBase提要:】
🚀 RLAIF技术介绍: Starling-7B采用了基于AI反馈的强化学习,通过优化Openchat3.5和Mistral-7B而成。
📊 性能卓越: 在基准测试中,Starling-7B表现出色,对比其他模型性能提升引人瞩目。
🔄 迈向人性化: RLAIF主要改善了模型的实用性和安全性,未来计划引入高质量的人工反馈数据,更好地满足人类需求。
👨💻💡🎯聚焦开发者
Keras3.0正式发布
Keras3.0发布,全面支持TensorFlow、JAX和PyTorch,进行了全新的大模型训练和部署功能引入,保持高度向后兼容性,为深度学习开发者提供更多选择和工具。
【AiBase提要:】
💡 全面支持多框架: Keras3.0全面支持TensorFlow、JAX和PyTorch,使用户可以选择在不同框架上运行Keras工作流。
💻 大模型训练和部署: 引入新的大模型训练和部署功能,支持各种预训练模型,保持高度向后兼容性,平滑过渡。
🚀 跨框架数据pipeline: Keras3.0支持跨框架数据pipeline,包括分布式API,提高在大规模数据并行和模型并行方面的效率。
中国团队开源大规模高质量图文数据集ShareGPT4V
中国团队开源了基于GPT4-Vision构建的图文数据集ShareGPT4V,训练了7B模型,涵盖120万条多样性丰富的图像-文本描述数据,在多模态性能上超越同级别模型,为多模态研究和应用提供了新的基石。

【AiBase提要:】
🌐 数据集概要: ShareGPT4V基于GPT4-Vision构建,包含120万条图像-文本描述数据,涵盖世界知识、对象属性、空间关系、艺术评价等多方面。
🚀 性能突破: 中国团队的7B模型在多模态基准测试上表现优异,超越同级别模型,为多模态研究和应用提供有力支持。
🔗开源资源: 该数据集已开源,论文地址为
https://arxiv.org/abs/2311.12793,项目地址为https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V
上海AI实验室、Meta联合开发开源模型 可为人体生成3D空间音频
上海AI实验室与Meta合作推出的开源模型利用头戴式麦克风和人体姿态信息,成功生成人体的3D空间音频,为虚拟环境提供关键支持。
项目地址:https://github.com/facebookresearch/SoundingBodies
【AiBase提要:】
🔍 技术突破: 上海AI实验室与Meta的开源模型通过多模态融合,解决了音源位置未知和麦克风距离音源较远等难题,成功实现了人体的3D空间音频生成。
🔒 局限性挑战: 虽然取得了技术进展,但该模型仅适用于渲染人体音,难以处理非自由音场传播环境,且计算量较大,难以在资源受限的设备上部署。
🌐 开源模型链接: 项目地址为 https://github.com/facebookresearch/SoundingBodies,为虚拟现实领域的发展提供了新的可能性,但仍需进一步优化和拓展。
Real-ESRGAN-Video:将视频清晰度提升至2K或4K
Real-ESRGAN-Video技术让用户轻松将视频清晰度提升至2K或4K,通过简化上传和选择清晰度的步骤,提供多种模型处理模式,特别适用于动画视频。测试结果显示对相对清晰的视频效果显著,为提升视频素材清晰度带来新可能。
【AiBase提要:】
🌟 清晰度提升: Real-ESRGAN-Video技术简化步骤,让用户轻松将视频清晰度提升至2K或4K。
🔄 多模型支持: 提供多种处理模式,标准模型适用于大多数视频,动画专用模型更擅长处理动画线条和颜色。
🚀 测试验证: 测试结果显示在相对清晰的视频上,提升效果显著,尤其对动画视频的效果提升更为明显。
- 0000
- 0000

 0002
0002- 0000

 0000
0000