研究人员发布Starling-7B:基于AI反馈的大语言模型 媲美GPT-3.5
**划重点:**
1. 🚀 **RLAIF技术介绍:** Starling-7B采用了基于AI反馈的强化学习(RLAIF),通过优化Openchat3.5和Mistral-7B而成。
2. 📊 **性能卓越:** 在MT-Bench和AlpacaEval两项基准测试中,Starling-7B表现出色,对比其他模型的性能提升引人瞩目。
3. 🔄 **迈向人性化:** RLAIF主要改善了模型的实用性和安全性,未来计划通过引入高质量的人工反馈数据,更好地满足人类需求。
UC伯克利的研究人员最近发布了Starling-7B,这是一款基于AI反馈强化学习(RLAIF)的开放式大语言模型(LLM)。该模型基于精调的Openchat3.5,并继承了Mistral-7B的特性。
在RLAIF中,研究人员借助其他AI模型的反馈来训练Starling-7B,以提升其聊天机器人响应的实用性和安全性。与以往ChatGPT中通过人类反馈进行的强化学习(RLHF)相比,RLAIF更具成本效益,速度更快,透明度更高,且可扩展性更强。
为了使用RLAIF训练模型,研究人员创建了Nectar数据集,其中包含183,000个聊天提示,每个提示有七个响应,总计3.8百万个成对比较。响应来自不同的模型,包括GPT-4、GPT-3.5-instruct、GPT-3.5-turbo、Mistral-7B-instruct和Llama2-7B。研究人员通过GPT-4对合成响应进行评分,并采用独特方法规避了GPT-4的偏见,将第一和第二响应评分最高。
Starling-7B在两个基准测试,MT-Bench和AlpacaEval中表现卓越。Starling-7B 在 MT-Bench 中的表现优于除 OpenAI 的 GPT-4和GPT-4Turbo之外的大多数模型,并且在 AlpacaEval 中取得了与 Claude2或 GPT-3.5等商业聊天机器人相当的结果。与普通 Openchat3.5相比,在 MT-Bench 中,分数从7.81增加到8.09,在 AlpacaEval 中,分数从88.51% 增加到91.99%。研究人员指出,RLAIF主要改善了模型的实用性和安全性,但并未影响其回答基于知识、数学或编码的问题的基本能力。
虽然基准测试结果在实际应用中有一定限制,但对于RLAIF的应用来说,结果仍然令人鼓舞。研究人员指出,下一步可能是通过引入高质量的人工反馈数据扩充Nectar数据集,以更好地调整模型以满足人类需求。
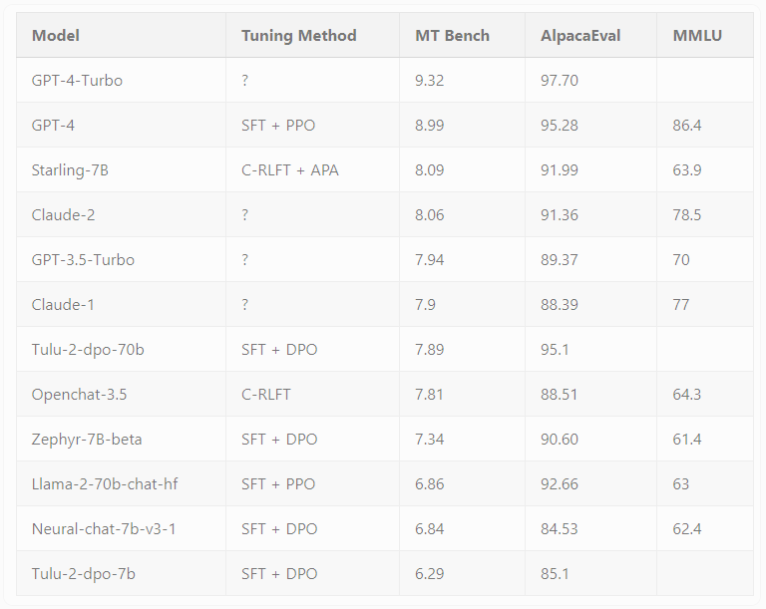
Starling-7B展示了AI反馈在强化学习中的潜力,为构建更符合人类喜好的模型打开了新的可能性。研究人员强调,尽管Starling-7B在一些需要推理或数学任务上仍存在困难,并有幻觉倾向,但其性能仍然可圈可点。
研究人员已经发布了Nectar数据集、与之相关的Starling-RM-7B-alpha奖励模型以及基于该数据集训练的Starling-LM-7B-alpha语言模型,这些可以在Hugging Face上获得。他们计划在不久的将来发布代码和论文,供研究使用。对于对模型进行测试,读者可以参与聊天机器人竞技场。
项目网址:https://huggingface.co/berkeley-nest/Starling-LM-7B-alpha


 0001
0001

 0000
0000- 0005
- 0000


 0000
0000

