DeepMind提出语言模型训练新方法DiLoCo 通信量减少500倍
要点:
DeepMind的研究团队提出了分布式低通信(DiLoCo)训练语言模型的方法,采用分布式优化算法,使语言模型在连接性较差的设备集群上训练,性能超过完全同步模型,通信开销减少500倍。
DiLoCo借鉴联邦学习文献,采用一种变体的联邦平均(FedAvg)算法,结合动量优化器,通过将内部优化器替换为AdamW和外部优化器替换为Nesterov Momentum,有效应对传统训练方法的挑战。
DiLoCo通过限制共位要求、降低通信频率和设备异构性等三个关键因素,实现了在多台设备可用但连接较差的情况下,分布式训练变压器语言模型的鲁棒性和效果,并在C4数据集上展现出与完全同步优化相媲美的性能。
DeepMind的最新研究在语言模型训练领域取得突破,提出了分布式低通信(DiLoCo)方法。这一方法采用分布式优化算法,使得语言模型可以在连接性较差的设备集群上训练,不仅性能超越完全同步模型,而且通信开销降低了500倍。为了实现这一创新,研究人员借鉴了联邦学习文献,提出了一种基于动量优化器的联邦平均算法的变体,通过替换内部和外部优化器,成功应对传统训练方法的工程和基础设施挑战。
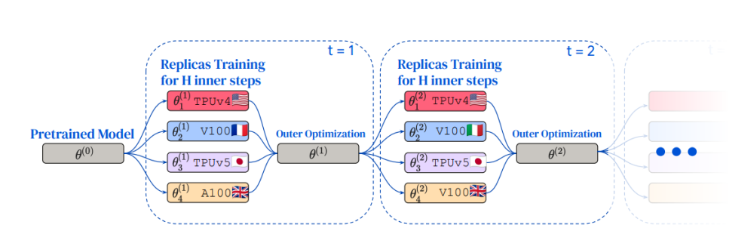
DiLoCo方法的关键优势体现在三个方面:首先,对设备的共位要求较低,减轻了后勤负担;其次,通信频率降低,工作者不需要在每一步都进行通信,大大减少了通信开销;最后,设备异构性的引入增强了灵活性,同一集群内的设备可以不同类型,提高了适应性。
在DiLoCo的训练过程中,通过复制预训练模型,每个工作者独立且并行地在自己的数据片段上训练模型。随后,工作者平均其外部梯度,外部优化器更新全局参数,这一过程重复多次。值得注意的是,每个复制品可以在不同的全局位置使用各种加速器进行训练。
在C4数据集上的实验证明,DiLoCo在8个工作者的情况下展现出与完全同步优化相当的性能,同时通信开销降低了500倍。此外,DiLoCo对每个工作者数据分布的变化表现出卓越的稳健性,并且能够适应训练过程中资源可用性的变化。
综合而言,DiLoCo方法为分布式训练提供了一个强大而有效的解决方案,特别是在多台设备可用但连接性较差的情况下。这一创新性的方法不仅克服了基础设施挑战,还展示出卓越的性能和适应性,标志着语言模型优化领域的重大进展。
- 0000
- 0000


 0002
0002- 0000
- 0001