研究:代码数据增强技术在深度学习中的应用具有巨大潜力
要点:
1、代码数据增强技术在深度学习中的应用具有巨大潜力,能够提高模型性能和稳健性。
2、代码数据增强面临着独特的挑战,包括代码的特殊性和多模态特性,但已经取得了一些令人鼓舞的成果。
3、代码数据增强方法主要分为基于规则的技术、基于模型的技术和示例插值技术,每种方法都有其特点和适用场景。
代码数据增强技术在深度学习中的应用已经取得了一些令人鼓舞的成果。代码模型通过训练大量的源代码语料库,能够模拟代码片段的上下文,已经在多个源代码的下游任务中显示出了出色的性能。代码数据增强技术通过数据合成来增加训练样本的多样性,从而提高模型的准确性和稳健性。
然而,与图像和纯文本不同,源代码受到编程语言严格句法规则的限制,增强的灵活性较低。因此,代码数据增强方法需要遵守特定的转换规则,以保持原始代码片段的功能性和语法。
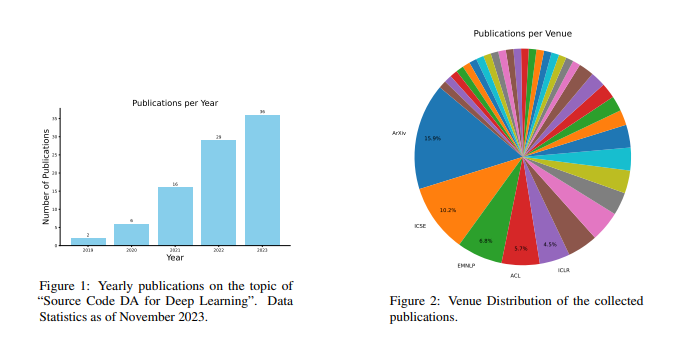
论文地址:https://arxiv.org/pdf/2305.19915.pdf
项目地址:https://github.com/terryyz/DataAug4Code
代码数据增强方法主要分为基于规则的技术、基于模型的技术和示例插值技术。基于规则的技术利用预定规则来转换程序,同时保证不破坏语法规则和语义。基于模型的技术通过训练各种模型来增强数据,例如生成对抗网络。示例插值技术通过插值输入和实际样本的标签来操作。
在实际应用中,设计和选择合适的数据增强方法受到多种因素的影响,例如计算成本、样本多样性和模型的稳健性。因此,优化和堆叠不同的数据增强策略是重要的。
代码数据增强技术的应用场景主要包括提升模型的稳健性和在低资源领域中的应用。通过生成对抗性示例来识别和减轻代码模型中的漏洞,可以提高模型的稳健性。在低资源领域,代码数据增强技术可以帮助解决资源匮乏的问题,提高模型的性能。综上所述,代码数据增强技术在深度学习中的应用具有巨大潜力,可以提高模型的性能和稳健性,但仍然需要进一步的研究和探索。
- 0000
- 0000
- 0000
- 0000
- 0000


