Vectara排行榜:OpenAI的GPT-4在文档摘要中幻觉率最低
**划重点:**
1. 📊 Vectara的排行榜显示,OpenAI的GPT-4在文档摘要中具有最低的幻觉率,准确率为97%。
2. 🚀 GPT-4和GPT-4Turbo表现最佳,GPT-3.5Turbo排名第二,Meta Llama为最高得分的非OpenAI模型,而Google Palm排名最后。
3. 🛠 Vectara发布了开源模型,允许任何人检查其大型语言模型的幻觉率,以提高生成式AI系统的可信度。
在一项由Vectara进行的开源模型评估中,OpenAI的GPT-4在文档摘要中表现卓越,凭借其出色的97%准确率和令人瞩目的3%的幻觉率,成为幻觉率最低的大型语言模型。
Vectara在GitHub上发布了一个排行榜,评估了一些大型语言模型在其“Hallucination Evaluation Model”上的表现,该模型衡量了语言模型在摘要文档时引入幻觉的频率。
排名第一的是GPT-4和GPT-4Turbo,它们分别以97%的准确率和3%的幻觉率脱颖而出。另一款OpenAI模型,GPT-3.5Turbo,排名第二,其准确率为96.5%,幻觉率为3.5%。
在非OpenAI模型中,最高得分的是Meta的Llama2,具有70亿参数,准确率达到94.9%,幻觉率仅为5.1%。
然而,谷歌的模型表现相对较差,Google Palm2的准确率为87.9%,幻觉率为12.1%。Palm的聊天优化版本表现更差,准确率仅为72.8%,幻觉率则高达27.2%。
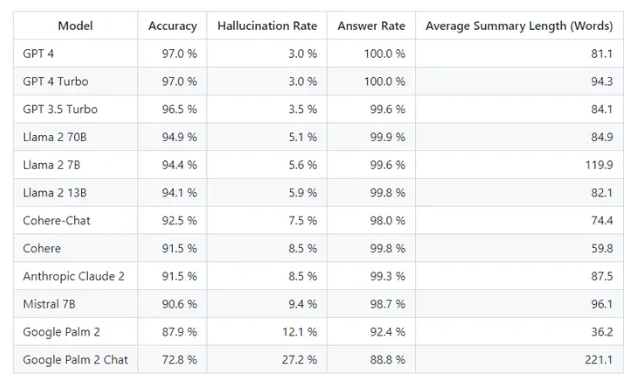
在摘要长度方面,Google Palm2Chat生成的平均摘要字数最高,达到惊人的221个字。相比之下,GPT-4仅生成每个摘要81个字。
Vectara是一家总部位于Palo Alto的公司,他们通过使用开源数据集培训了一个模型,以检测大型语言模型输出中的幻觉。该公司通过其公共API向每个模型提供了1000个短文档,并要求它们仅使用文档中呈现的事实进行摘要。
在这1000个文档中,只有831个被每个模型摘要,其余的文档由于内容限制被至少一个模型拒绝。Vectara随后计算了每个模型的总体准确率和幻觉率。
Vectara的“Hallucination Evaluation Model”是开源的,意味着企业可以使用它来评估其大型语言模型在检索增强生成(RAG)系统中的可信度。用户可以通过Hugging Face访问该模型,并根据自己的需求进行调整。
项目网址:https://huggingface.co/vectara/hallucination_evaluation_model
Shane Connelly,Vectara的产品负责人在博客中写道:“幻觉的风险阻碍了许多企业采用生成式AI。我们的目标是通过量化分析为企业提供他们需要的信息,使他们能够通过有信心地启用生成系统。”

 0000
0000- 0000
- 0005
- 0000
- 0000