中科大联合封神榜团队发布中文医疗领域大模型ChiMed-GPT
站长网2023-11-20 16:46:150阅
中科大和 IDEA 研究院封神榜团队合作开发了一款名为 ChiMed-GPT 的中文医疗领域大语言模型(LLM)。该模型基于封神榜团队的 Ziya2-13B 模型构建,拥有130亿个参数,并通过全方位的预训练、监督微调和人类反馈强化学习来满足医疗文本处理的需求。
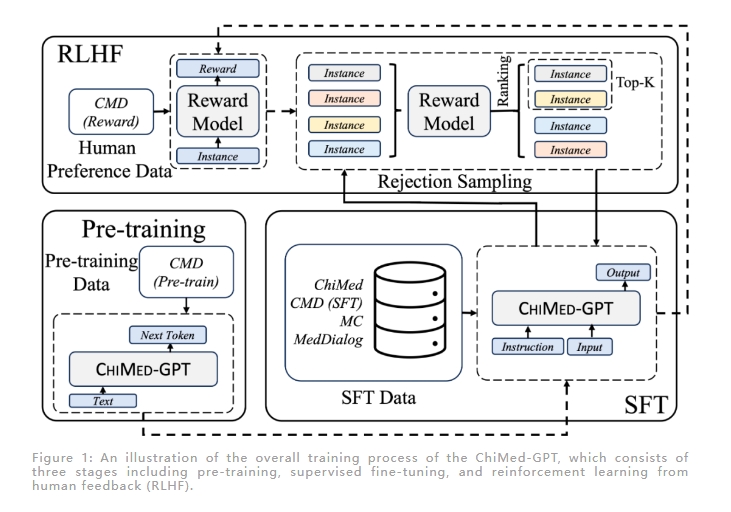
ChiMed-GPT 的训练过程包括三个阶段:预训练、监督式微调和人类反馈强化学习。在预训练阶段,模型使用了2.14亿字的医学百科文档和教科书文章进行继续训练,以扩展医疗领域的知识。在监督式微调阶段,模型利用问答和医患对话数据来提升在真实医疗环境中理解人类指令的能力。在人类反馈强化学习阶段,模型使用拒绝采样技术进行训练,通过奖励模型训练和拒绝采样微调来进一步提高模型性能。
在医疗信息抽取、问答和对话生成等任务上,ChiMed-GPT 的性能优于其他同规模的开源模型,并且在多个指标上超越了 GPT-3.5。在医疗信息抽取任务中,ChiMed-GPT 的性能优于通用和医学领域的开源模型。在问答任务和对话生成任务中,ChiMed-GPT 在多个评估指标上表现出色,展示了其在实际应用中的广泛适用性。
据悉,ChiMed-GPT 的研发对于提升医疗智能的重要性具有重要意义。该模型不仅能够有效处理医疗文本数据,还能生成适合回答患者咨询的内容。
Github:
https://github.com/synlp/ChiMed-GPT
HuggingFace:
https://huggingface.co/SYNLP/ChiMed-GPT-1.0
0000
评论列表
共(0)条相关推荐
- 0000
- 0000

 0001
0001- 0000


 0000
0000