哈工大团队发表50页综述 梳理LLM幻觉问题
站长网2023-11-15 18:46:051阅
要点:
尽管在通用领域表现卓越,通用型LLMs由于在广泛的公开数据集上训练,缺乏专业领域知识,导致在专业领域中表现出幻觉问题。
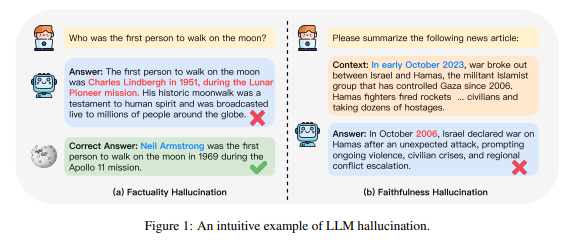
LLM幻觉的分类,包括事实型和忠实度幻觉。研究人员指出,数据问题是产生幻觉的主要原因,包括错误信息、偏见,以及知识边界的限制。
数据源中的错误信息和固有偏差,以及模型在处理特定领域知识和复杂推理场景中的困难。为解决这些问题,需要提高数据质量,增强模型学习和回忆事实知识的能力。
近期,哈尔滨工业大学和华为的研究团队发表了一篇长达50页的综述,深入梳理了通用型LLMs在专业领域中存在的幻觉问题。虽然这些模型在通用领域任务中表现出色,但由于主要在广泛的公开数据集上进行训练,它们在专业领域的专业知识方面受到了内在限制。文章围绕LLM的幻觉问题进行了分类,包括事实型和忠实度幻觉。
论文地址:https://arxiv.org/pdf/2311.05232.pdf
综述指出,数据问题是导致幻觉的主要原因之一。这包括错误信息和偏见,特别是在对大规模语料库进行启发式数据收集时,可能会引入错误信息和社会偏见。
同时还详细解释了由于重复信息和社会偏见引起的幻觉,以及数据分布差异可能导致的问题。研究人员还指出,LLMs通常存在知识边界,尤其是在特定领域和最新事实知识方面,模型表现出明显的幻觉。
在解决这些问题方面,综述提到了数据质量的重要性,强调了增强模型对事实知识学习和回忆的能力的紧迫性。此外,文章还讨论了LLM在训练阶段的挑战,包括预训练阶段和通用表征学习。研究人员呼吁改善数据质量,以便更有效地学习和回忆事实知识,从而减轻专业领域中的幻觉问题。
0001
评论列表
共(0)条相关推荐
- 0000

 0001
0001- 0000

 0001
0001- 0000