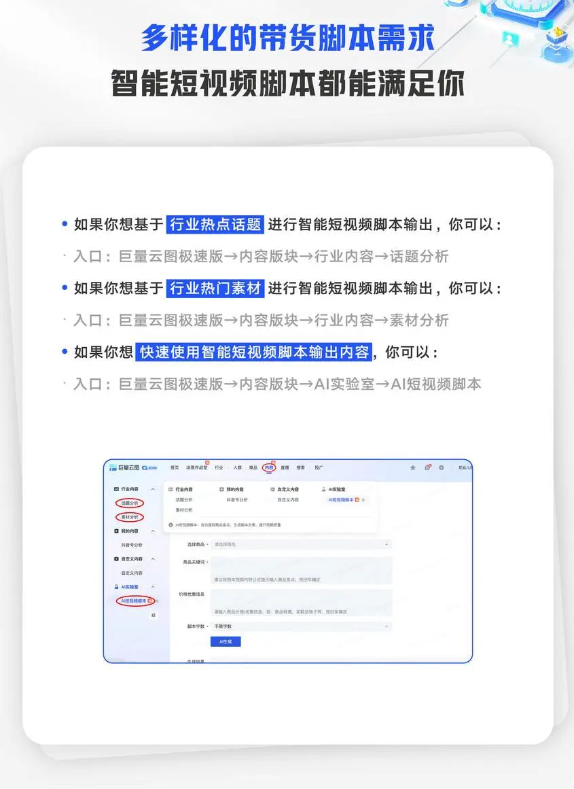
牛!S-LoRA技术实现单GPU运行数千个LLM,个性化服务AI应用
**划重点:**
1. 🌐 S-LoRA技术由斯坦福大学和加州大学伯克利分校的研究人员合作开发,可显著降低LLM精细调整的成本,使企业能够在单个GPU上运行数百甚至数千个模型。
2. ⚙️ S-LoRA通过动态内存管理系统和"Unified Paging"机制解决了部署多个LoRA模型时的技术挑战,支持在单个GPU或多个GPU上服务多个LoRA适配器。
3. 📈 在评估中,S-LoRA相较于Hugging Face PEFT表现出色,提高了30倍的吞吐量,并成功同时服务了2,000个适配器,为个性化LLM服务在企业应用中创造了可能。
近日,研究人员在解决大型语言模型(LLM)精细调整的高成本和计算资源限制方面取得了重要突破。由斯坦福大学和加州大学伯克利分校的研究人员合作开发的S-LoRA技术,使得在单个图形处理单元(GPU)上运行数千个LLM模型成为现实。
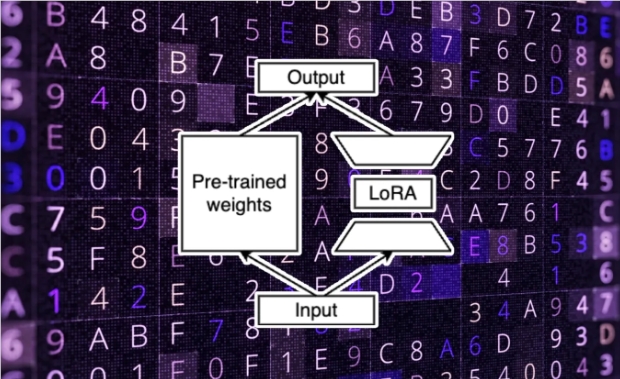
通常,对LLM进行精细调整是企业定制人工智能功能以适应特定任务和个性化用户体验的重要工具。然而,这一过程通常伴随着巨大的计算和财务开销,限制了中小型企业的应用。为解决这一难题,研究人员提出了一系列算法和技术,其中S-LoRA技术成为最新的亮点。
S-LoRA采用了LoRA的方法,该方法由Microsoft开发,通过识别LLM基础模型中足够用于精细调整的最小参数子集,将可调整参数数量减少数个数量级,同时保持与全参数调整相当的准确性水平。这极大地减少了个性化模型所需的内存和计算资源。
尽管LoRA在精细调整中的有效性已经在人工智能社区广泛应用,但在单个GPU上运行多个LoRA模型仍然面临一些技术挑战,主要是内存管理和批处理过程。S-LoRA通过引入动态内存管理系统和"Unified Paging"机制成功解决了这些挑战,实现了多个LoRA模型的高效服务。
在评估中,S-LoRA在服务Meta的Llama模型时表现出色,相较于Hugging Face PEFT,吞吐量提高了30倍,同时成功服务了2,000个适配器,而计算开销增加微不足道。这使得企业能够以较低的成本提供个性化的LLM驱动服务,从内容创作到客户服务等领域都有广泛应用前景。
S-LoRA的研究人员表示,该技术主要面向个性化LLM服务,服务提供商可以通过相同的基础模型为用户提供不同的适配器,这些适配器可以根据用户的历史数据进行调整。此外,S-LoRA还支持与上下文学习相容,通过添加最新数据作为上下文,进一步提升LLM的响应效果。
该技术的代码已经在GitHub上开源,研究人员计划将其整合到常见的LLM服务框架中,以便企业能够轻松地将S-LoRA纳入其应用中。这一创新为企业提供了更广阔的LLM应用空间,同时降低了运行成本,推动了个性化AI服务的发展。
- 0001
- 0000
- 0000
- 0000
- 0000