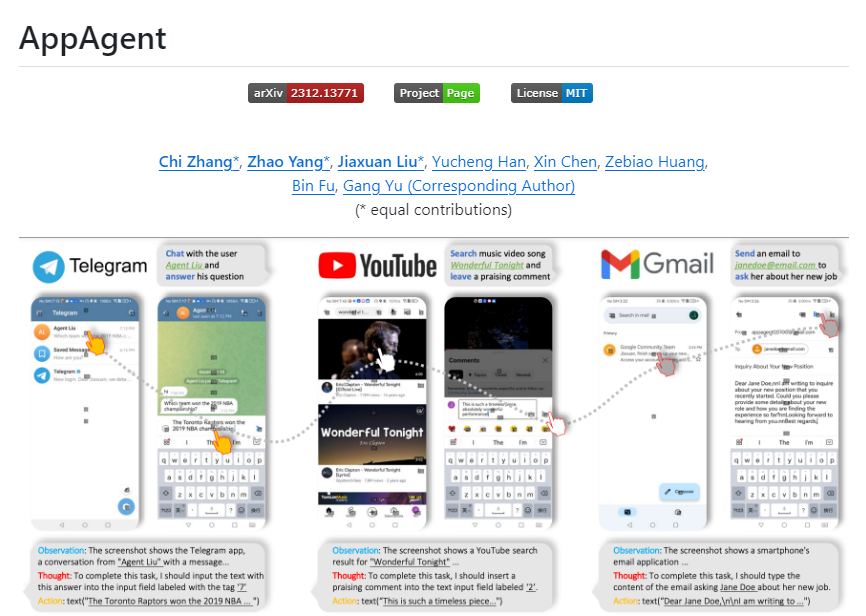
北大腾讯提出多模态对齐框架LanguageBind
要点:
1、北京大学与腾讯等机构研究者提出了多模态对齐框架LanguageBind,并在多个榜单中取得了优异表现。
2、多模态信息对齐面临挑战,需要将不同模态信息进行整合与对齐,而新框架通过语言作为中心通道实现了多模态信息的语义对齐。
3、研究团队构建了VIDAL-10M数据集,这是一个大规模、多模态数据对的数据集。
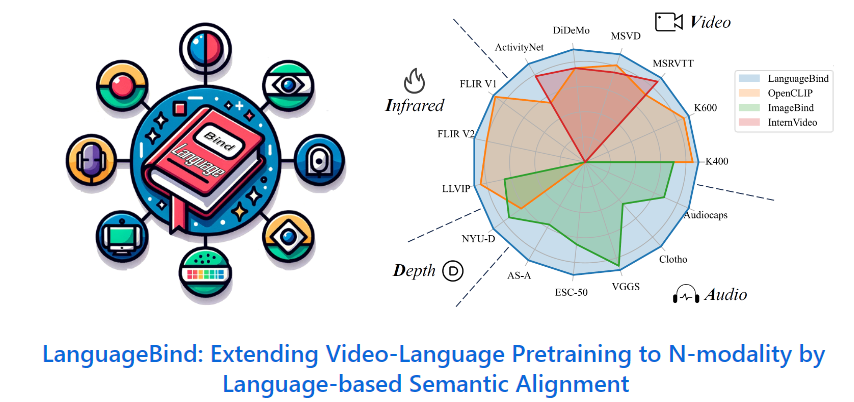
北大腾讯等提出了多模态对齐框架LanguageBind,这一新框架在多个榜单中获得卓越表现。在现代社会,信息传递和交流不再局限于单一模态,而是多模态的。由于信息交互的复杂性,如何让机器理解和处理多模态的数据成为人工智能领域的前沿问题。
当前主流的对齐技术通常会导致性能次优化,因此北大腾讯的研究团队提出了一种新的多模态对齐框架——LanguageBind,该框架利用语言作为不同模态信息对齐的纽带。在这个框架下,语言不再是附属于其他模态的标注或说明,而是成为了联合不同模态的中心通道。
项目地址:https://github.com/PKU-YuanGroup/LanguageBind
并通过将所有模态的信息映射到一个统一的语言导向的嵌入空间,实现了不同模态之间的语义对齐。该框架还构建了VIDAL-10M数据集,包含了视频 - 语言、红外 - 语言、深度 - 语言和音频 - 语言配对,以确保跨模态的信息是完整且一致的。在多模态信息处理领域,LanguageBind的提出为多模态预训练技术的发展奠定了坚实基础。
该框架摒弃了依赖图像作为主导模态的传统方法,而是直接利用语言模态作为不同模态之间的纽带。通过一系列优化的对比学习策略,LanguageBind实现了直接的跨模态语义对齐。这种方法避免了通过图像中介可能引入的信息损失,提高了多模态信息处理的准确性和效率。
此外,该研究团队构建了VIDAL-10M数据集,这是一个大规模、包含多模态数据对的数据集,涵盖了视频 - 语言、红外 - 语言、深度 - 语言和音频 - 语言等数据对。并经过了精心的质量筛选,确保了数据集的高品质和高完整性。这一举措为跨模态预训练领域提供了一个高质量的训练基础。对于多模态对齐框架LanguageBind的提出,有望为多模态学习领域带来重要的进展和突破。
- 0000


 0000
0000
 0000
0000- 0004
- 0000