天玑9300拿下生成式AI最强移动芯,端侧支持330亿大模型,1秒内AI画图,全新全大核架构做底座
最强生成式AI终端芯片,现已易主!
天玑9300一举支持运行最大330亿参数大模型,短短几周时间内刷新业界纪录。

它是业界首款搭载硬件生成式AI引擎,首次实现端侧LoRA融合,让大模型技能可在本地扩展,基于个人照片生成专属表情包。

打开摄像头,即可实时生成一个虚拟数字分身。

同样支持1秒内文生图、20Tokens/秒生成文本(70亿参数)。

并且拿下“业内第一移动AI性能”,设备AI 跑分达到恐怖的3173(目前业内公开最好成绩为2000 ).

没想到,联发科首颗生成式AI移动芯片,性能就如此强悍。
加上首次采用的全大核CPU架构,天玑9300属实是把牙膏踩爆了,峰值性能较上一代提升40%,功耗节省33%。
网友们看了都直呼:发哥,稳了!

搭载天玑9300的旗舰智能机vivo X100系列,马上就会和大家见面。
如果你想尝鲜,确实值得期待一把。
因为这是一张从底层开始、完全为生成式AI而来的旗舰级移动芯片。
透过它,不仅能先人一步体验在端侧玩大模型有多丝滑;更能提前窥见与感受,AI浪潮和移动终端将会碰撞出哪些激烈火花,。
手机实时生成虚拟分身
作为一张生成式AI移动芯片,能带来哪些创新体验?
天玑9300先来打个样,带来如下几方面能力:
支持运行大模型
快速文本、图像生成
端侧能力扩展、个人专属GIF表情包
视频实时个人分身
生成式超分、夜景防眩光
语意搜索

最基本的,生成式AI芯片要具备端侧支持大模型的能力。
天玑9300支持终端运行10亿、70亿、130亿、最高330亿参数AI大模型。
通过和vivo的深度合作,基于天玑9300率先实现了在vivo旗舰手机上端侧落地70亿参数大语言模型,系行业首家。
同时也突破行业上限,和vivo一起将端侧运行大模型规模提高到130亿参数。
在可以运行的基础上,更进一步,需要做到快速处理。
天玑9300具备快速文字、图片生成能力。
70亿参数模型下可实现每秒20Tokens输出,支持文本创作、摘要生成等文本任务。
每张图片生成时间控制在1秒以内。
这意味着几乎无需等待,就能马上从手机上获得最新AI生成结果。

这也是为什么天玑9300能拿下业界移动AI性能第一名号,ETHZ AI Benchmark v5.1Mobile SoC >2000分。

更创新的体验来自端侧技能扩展,它支持在本地生成多样个性化内容。
这也是移动芯片首次实现端侧LoRA。
基于此,拍下一张照片,在手机本地即可进行各种风格处理,生成个人专属表情包。

要知道,基座大模型的知识与能力相对有限,想要让大模型有更强生产力,往往需要对大模型进行SFT、LoRA等方式微调。今年AI绘画能凭借不同画风、多次掀起热潮,很多程度上正是得益于LoRA方法。
天玑9300的端侧支持,可以让LoRA变得更加便捷,可以推动大模型在手机上实现更多丰富玩法。
除此之外,生成式AI的应用还能导入到视频中,实时生成个人虚拟化分身,进行视频通话。

一些已有的AI应用,也基于生成式AI实现了更多创新。
比如用在提升游戏画质、图像方面的超分算法,使用生成式能力后可以带来更好画质提升;

夜景拍摄可以防眩光产生;

以及生成式AI语意搜索,能不联网智能检索相册图片,在端侧完成计算更好保护隐私。

总之,透过天玑9300的能力可以感受到,联发科认为一张合格的生成式AI移动芯片,应该能把大模型能力尽可能带到端侧。
不只是要装下更大模型,还要让大模型能在端侧拓展能力,以此带来更丰富的应用。
那么,联发科是如何做到?
第七代APU 全大核打底
作为一张为生成式AI而来的移动芯片,天玑9300的能力提升逻辑简单粗暴:
AI性能拉满,底层能力夯实。
具体可以从APU和整体架构两个方面来看。
APU主要负责实现大模型的端侧快速运行。
天玑9300集成MedieTek第七代AI处理器APU790,整数运算和浮点运算性能均是上一代的2倍,同时功耗降低45%。

为了能让端侧支持更大规模大模型,它带来了特有的内存硬件压缩技术(NeuroPilot Compression)。
要知道,大模型的海量数据在带来极致性能同时,也带来了巨大内存占用。所以这也是为什么大模型进端侧难。
联发科先采用INT4量化,将130亿参数大模型压缩至13GB。
然后基于内存硬件压缩,进一步把13GB内存压缩到只有5GB,内存占用直降61%。
这样一来,内存为16GB的内存即可运行130亿参数大模型,24GB内存手机可运行330亿参数大模型。

但装下大模型还不够,联发科认为还要让大模型具备更丰富能力。
由此提出了生成式AI端侧“技能扩充”技术(NeuroPilot Fusion)。
它直接解决了终端无法装下过多大模型的问题,实现一个大模型为底座,N个技能作为扩展。
这样既解决了大模型的内存瓶颈,还尽可能拓展手机上生成式AI的应用边界。

而为了能让大模型更丝滑地在终端运行,天玑9300在更底层还做了进一步优化。
一方面,天玑9300是业界首款硬件生成式AI引擎。
它深度适配Transformer模型,特别在Softmax LayerNorm算子上,处理速度较上一代提升8倍。
Softmax LayerNorm算子正是当下大语言模型(Transformer网络)的核心部分。
另一方面,天玑9300开创性采用了全大核CPU架构,从底层大幅提升芯片算力。
它包含4个 Cortex-X4超大核,最高频率可达3.25GHz,以及4个主频为2.0GHz的Cortex-A720大核,其峰值性能相较上一代提升40%,功耗节省33%。

其单个E大核的能效比完全超越传统架构B核和L核。
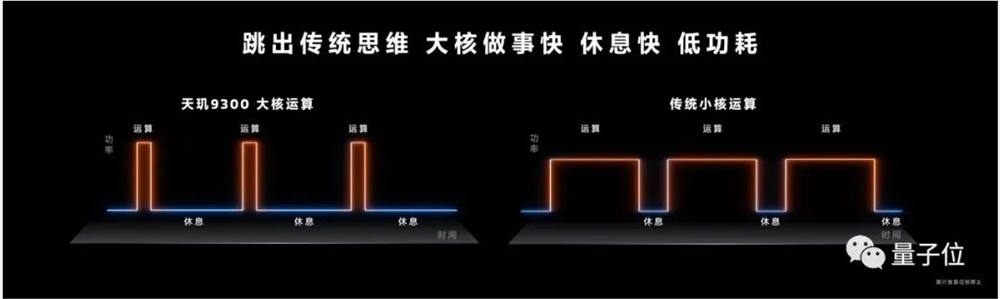
全大核架构全面使用乱序执行(out-of-order)内核。
和传统小核必须顺序执行的逻辑不同,大核运算允许只要任务进来且可以处理,它就会开始执行。
这样能大幅减少任务的总消耗时间,提升应用执行效率、减少卡顿。同时也能降低功耗,对比如下两图,大核运算“做得快、休息快”,运行曲线的积分更小,即功耗更低。

这些能力都能为芯片执行生成式AI任务,提供扎实的基础计算底座。
最后,生成式AI在端侧运行,还有很多细节需要考量。
比如在交互方面,目前大模型更多以智能助手形象出现,语音是重要的交互方式之一,所以天玑9300专门提升了音频降噪能力,支持对3个麦克风动态录音降噪,可以有效过滤风噪等环境音,不仅能让视频拍摄、录音效果更好,也能辅助提升大模型语音识别的正确率。

另外在用户格外关注的数据安全方面,天玑9300集成双安全芯片,从开机源头保护个人隐私,同时具有物理隔离计算环境,进一步保障个人数据加密、解密的安全。以及内存标记扩展(MTE)技术,可以打造更安全的开发环境。

如上诸多方面的优化、革新与考量,都让天玑9300成为一块名副其实为生成式AI而来的移动芯片。
而除了对自身硬件性能提升,联发科还进一步打通大模型生态。
支持Meta LLaMA2、百度文心一言大模型、百川大模型等前沿主流AI大模型,以及多模态大模型。
应用方面和抖音、快手、虎牙、爱奇艺、美图秀秀等展开合作,提供相关SDK和model hub。

开发者生态方面,天玑开发者中心将提供端侧生成式AI落地的一站式资源,提供端侧部署案例分享。目前已有20 生成式AI合作伙伴。
一言以蔽之,联发科要用天玑9300这块旗舰芯,正式叩开生成式AI大门。
由此带来的影响,将从联发科由内至外,给全行业带来新气息,更进一步影响到每一位智能手机用户。
生成式AI打开移动芯片新象限
在近几年里,手机行业始终在思考一个大命题,下一代旗舰机该怎么做?
这个命题需要芯片、手机、应用等厂商共同思考,如折叠屏、旗舰影像等都是摸索出来的方向。
而生成式AI浪潮的到来,让这个大命题回归本源,即下一代智能手机,就是要更智能、更强大。
大模型是实现这一切的根本。
所以过去一段时间里,手机厂商们纷纷开始推出端侧大模型、发布接入大模型的OS系统,掀起大模型浪潮的OpenAI被曝要做新一代智能手机。
但落地到实际,怎么让手机用户能更好用上大模型。这个核心问题,还是要抛给芯片厂商。
因为大模型落地,必须要解决计算瓶颈、功耗瓶颈,而且只依靠云端运行不能长久,也不能从根本上打开大模型的手机场景。
从当下来看,联发科等头部手机芯片厂商已经迈出了关键性的第一步——将大模型实现端侧运行。
那么接下来该怎么走?如何思考生成式AI芯片的未来?以及大模型在手机端的应用?
现在似乎很难有非常明确的答案。
毕竟业内都非常清楚,大模型浪潮如今才只是最早期阶段,无论是技术层面还是应用落地,都仍需长期探索。
但联发科用天玑9300给出了一个关键参考:
面向生成式AI的移动芯片,要从底层为大模型做准备,“天生”更适合大模型,同时硬件层面要做到能力溢出。
为什么?
用联发科的话来说,就是“生成式AI旗舰芯片未来一定会有更多应用模式产生、完成更复杂的任务。”
作为一个硬件级的底座,要足够强大,上层系统、应用才能有更多创新空间,更多生成式AI端侧应用才能诞生。
在强大的同时,还要动作够快。
天玑9300不仅和vivo一同实现业内首个70亿大模型端侧落地,还实现了130亿参数大模型端侧运行。
搭载天玑9300的vivo X100系列也将马上上市。届时就能真正上手实测大模型跑在端侧是什么感觉了。
对于大模型上手机,你有哪些期待?对于今年生成式AI给手机行业带来的新气息,你又有哪些感受?
欢迎评论区留言讨论~
- 0000


 0000
0000- 0000
- 0000
 0000
0000