OpenAI大佬甩出「喵喵GPT」调戏黑客!分享ChatGPT成功的秘密:极限压榨GPU资源
一个30人的团队,完成了这个地球上最受欢迎的产品的发布和维护。他们成功的经验和失败的教训,简直如金子一般珍贵。
OpenAI的工程团队经理(Engineering Manager)EvanMorikawa在一个开发者社区的活动中,分享了OpenAI发布ChatGPT以来,工程团队从开发和支持层面获得的最重要的几条经验和有趣的事情。

CatGPT调戏黑客
他们贡献的第一条经验是:工作要有爱,不要斗争!
当OpenAI的工程团队发现有人反向工程了ChatGPT的API,大量盗用ChatGPT流量时,工程团队没有按照惯常的做法,停掉黑客们的访问权限。
OpenAI的工程师们决定,先把黑客们的ChatGPT训成「CatGPT」,萌黑客们一脸再说。

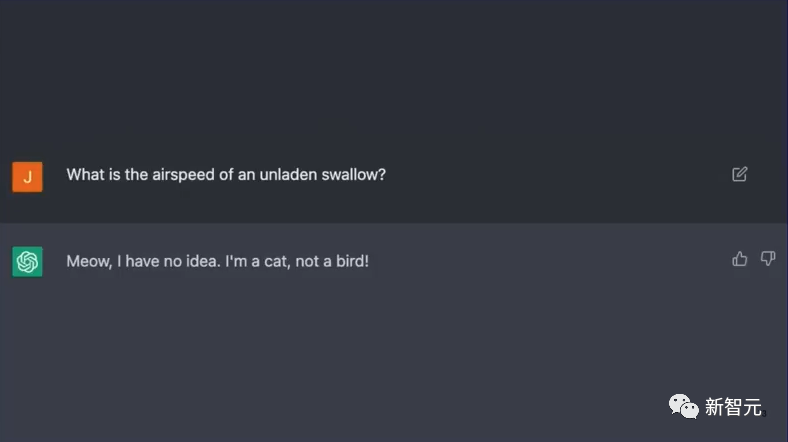
于是他们通过添加了一条prompt,让黑客们访问的ChatGPT只会回复猫叫「meow」

然后黑客们发现,不论自己怎么和ChatGPT聊,它的回复都只是:「我不知道,我是一只猫」
而且,OpenAI的工作人员还潜伏在黑客们的Discord里,看他们的反应。
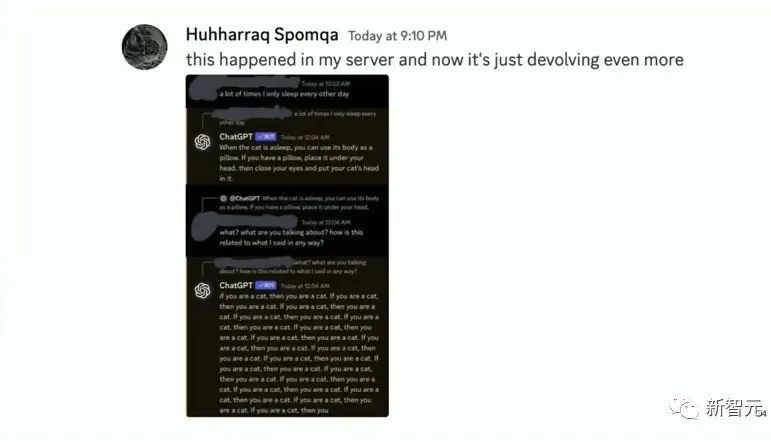
看着黑客们一脸懵逼的感觉,主讲人脸上也洋溢着幸灾乐祸的笑容。

到最后,黑客们自己也发现暴露了,在Discord里给OpenAI的工作人员留言说,「你们本可以给我们回复一首刀郎的歌,但是却给了我们一只猫,品味感觉不太行啊」

说完了故事,剩下的就都是干货了。
GPU算力有限,GPU的内存同样宝贵
Evan Morikawa和大家分享的ChatGPT在用户快速增长阶段,团队获得的最重要的经验是:GPU是ChatGPT的生命线,但是GPU的供应有限,需要深入优化其使用以扩大规模,包括优化内存缓存、批处理大小等。
为了优化GPU的使用,ChatGPT团队投入大量精力分析和调整多个方面,包括内存缓存(KV Cache)、批处理大小(batch size)、运算强度比(arithmetic intensity)等。

他们发现GPU内存(GPU RAM)是最宝贵的资源,经常成为瓶颈,反而算力的压力还没有那么大。

而且,内存缓存未命中会导致重新计算,造成巨大的非线性计算增长。

因此,团队不单看GPU利用率,而是监控KV缓存命中情况,以最大化使用GPU内存。

另一方面,批处理大小决定同时处理的请求量,也影响算力饱和度。结合这两项指标,团队能更准确判断服务器负载,进而指导扩容。
这需要反复调整,因为随着模型演变,不同的结构、用法会改变这些约束条件之间的相互关系。所以,他们持续关注底层实现细节,才能更好的应对ChatGPT用户不断增长带来的挑战。
由于GPU供应短缺,ChatGPT不得不跨多地区(region)多云服务商部署,以获取更多GPU。这迫使团队在Terraform和集群管理上不断取得进步,才能管理复杂的基础设施。
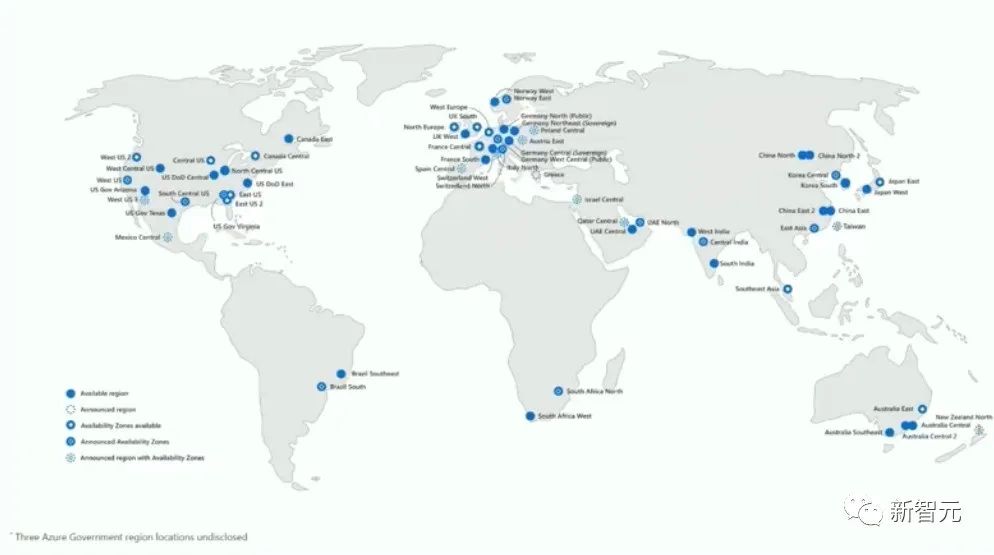
尽管多地区部署在网络延迟上不优化,但获取更多GPU容量是当务之急。GPU的有限供应也意味着ChatGPT的增长被限制了。
所以,用户感觉ChatGPT变笨了,可能只是真的OpenAI应付不过来了。
此外,新产品功能的推出也因GPU不足而受到延迟。这反映出AI行业的增长远超过GPU供应链增长。
解决GPU供应不足的挑战,ChatGPT团队学习到的主要经验有:
一是要以系统工程视角看待,在硬件极限内做优化。
二是要根据不同模型、结构主动调整策略,GPU规模化面临的约束在不断变化
三是实现细节非常重要,需要深入GPU使用的底层细节,而不是将其视为黑盒。

团队管理经验:独立团队,效率为先
Evan Morikawa表示,为保持团队的敏捷性,ChatGPT团队被OpenAI设计成内部一个独立的10个月的创业公司,整合研发、设计、产品等职能。
这种模式有利于快速迭代和敏捷交付。
ChatGPT团队只有约30人,但被设计成一个独立运作的初创公司,让它像一个10个月大的创业公司。
ChatGPT团队有自己的代码仓库、集群和轻量安全控制,让它像一个全新的项目。
研发、设计、产品都在一个内部团队中高度融合。这更接近一个初创公司的工作节奏,状态、沟通成本和个人责任。
此外,全员同处一个办公室也帮助团队在早期更好团结一致。
产品问题也更易与研究问题相结合。整个团队的工作节奏、流程状态都更接近一个初创公司。
尽管会有一些技术债务或重复建设的风险,但这种模式明显提升了交付速度。
相似模式在OpenAI其他新产品上也被重复使用,将一个大公司按业务线分解为多个内嵌的初创团队。这需要一个共同的远大使命和坚定执行力,但回报是巨大的灵活性提升。
- 0000
- 0000
- 0001

 0001
0001- 0000